7 Hvordan arbejder vi med tekst i R?
Historiefagets metoder er udviklet gennem arbejde med skrevne tekster. Selvom historikere har interesseret sig for andre former for data (tal, billeder etc.), har det skrevne ord altid haft en særligt priviligeret position. Det er som regel gennem fortidens papirarbejde, at vi studerer samfund og processer - både fordi vi ved, at papir har været medskaber af historien, men også fordi sporet af skrevne ord simpelthen ofte er hvad, der er tilbage af de verdener, vi undersøger.
Vi behøver heldigvis ikke holde op med at interessere os for det nedskrevne, blot fordi vi arbejder i et programmeringssprog. Faktisk er det måske netop i arbejdet med tekst, at sådanne værktøjer giver os nye muligheder. Måske kan vi tænke det sådan, at programmeringsværktøjer gør os i stand til at udforske skrevne tekster på nye systematiske måder, der kan være med til at kvalificere vores kildekritiske læsning. Nok elsker vi det skrevne ord, men vores øjne bliver alligevel trætte. Computeren bliver ikke træt, med mindre vi virkelig presser den. Tænk computeren som en nærmest uendeligt arbejdsom assistent.
Dette kapitel introducerer til nogle grundlæggende greb i forhold til, hvordan vi håndterer tekst i R. Disse greb er kompatible med de grundverber, du lærte i kapitel 2. Til sidst i kapitlet, samt i næste kapitel, eksemplificeres nogle simple arbejdsgange, der låses op af din computers fantastiske tålmodighed (når du får lyst til at se Netflix, gå en tur eller shoppe sko, fortsætter din computer bare… den er utrolig).
Data til kapitlet hentes her:
7.1 Setup
Vi starter som altid med at loade pakker og data. Datasættet indeholder en række kolonner, men i denne sammenhæng bruger vi udelukkende kolonnen “Text” og smider derfor resten ud. Vi kigger også på de 10 første observationer: Hvad er det for noget tekst, fortiden har efterladt os?
library(tidyverse)
library(readxl)
df <- read_excel("data/Signalement.xlsx") %>%
select(Text)
df$Text[1:10] [1] "Jndkom d: 24 Decbr: 1783. Han er föd i Kiöbenhavn, 34 Aar, 65 Tommer Höy, er i övrigt Ivalid og kan hverken gaae eller see."
[2] "Jndkom d: 9d Juny 1790. Han er föd i Kiöbenhavn, 31 Aar, 58 Tommer höy, stærk af skuldre og been, rundt Ansigt, brune Haar, og blaae Øyne, meddelmaadig Næse, almindelig Mund, tatuert paa begge Arme; ugivt"
[3] "Jndkom 28 Sept: 1792. Han er föd i Huusbye i Fyen 18 Aar, 62 3/4 tommer höy, proportionert af skuldre og been, blunde Haar og blaae Øyne, rundt Ansigt, meddelmaadig Næse, liden Mund og et lille Ar paa det venstre Øyenbryn, ugivt"
[4] "Jndkom 15 Janv. 1793; föd i Kiöbenhavn, 42 Aar, 62 3/4 tommer, proportionert af skuldre og been, rundt mavert Ansigt, liden Næse almindelig Mund, brune Haar og blaae Øyne, har krudpletter paa det venstre kind, gaar duknakket."
[5] "Jndkom 26 Febr. 1794; föd i Kiöbenhavn, 21 Aar, 62 1/4 tommer, proportionert af skuldre og been, rundt rödladet Ansigt, sorte Haar og brunt Øyne, maadelig Næse, stor Mund."
[6] "Jndkom 23 July 1794; föd i Haslev i Siælland, 36 Aar. 63 tommer, smal af skuldre og been, lille mavert Ansigt, sorte Haar og blaae Øyne, stor Næse almindelig Mund, en Vorte paa det Höyre kind, og et Ar over det höyre Øye."
[7] "Jndkom 27 Decbr. 1794; föd i Kiöbenhavn, 23 Aar, 64 tommer, stærk af skuldre og been, skrulrygget, lidet rundt Ansigt, meddelmaadig Næse, almindelig Mund, lyse Haar men skaldet, blaae Øyne"
[8] "Jndkom 28 Aug: 1795, föd i Haral Skiær Fabrique Skive Sogn i Jylland, 46 Aar, 64 1/4 tommer, bred af skuldre og smal af been, rundt rödladent Ansigt, meddelmaadig krum Næse, lille Mund, brune Haar og blaae Øyne, er givt og har en Sön og en Datter."
[9] "Jndkom 1 April 1796, föd i Worde paa Falster. 54 Aar; en Kröbling og kan ikke gaae fordi begge födderne ere affrosne."
[10] "Jndkom 11 April 1796, föd i Kiöbenhavn, 36 Aar, 58 1/2 tommer proportionert af Skuldre og been, langt mavert Ansigt, mörke Haar og blaae Øyne, stor Næse og stor Mund med fremstaaende Lipper, og har et Aasyn som om han var forrykt." Datasættet er en 1 til 1 transkription af en signalementsprotokol holdt ved fænglset Stokhusslaveriet. Det blev startet i 1807, men indeholder signalementer af fanger indsat længe før dette, i tilfælde hvor disse stadig var indsat, da protokollen blev startet. Datasættet inkluderer alle signalementer ført indtil 1832. Optegnelsen af kropsbeskrivelsen var en central del af indsættelsesritualet. Det havde den eksplicitte funktion, at man dermed kunne efterlyse eventuelle flugtfanger - f.eks. i tidens aviser.
7.2 Str_count
Når vi arbejder med tekst bruger vi ofte en serie af funktioner, der alle starter med “str_”. Dette er vores grundverber. Vi taler ofte om tekst som “strenge”, og “str” står for “string”.
Hvordan tæller vi teksstrenge? Det kan vi gøre vha. funktionen str_count. Denne kigger efter en formulering i form af en såkaldt regular expression. Strengen “\\w+” leder efter tal og bogstaver og tæller dem i “klumper”. Dette betyder reelt, at vi kan tælle antallet af ord.
df <- df %>%
mutate(antal_ord = str_count(Text, "\\w+"))
ggplot(df) +
geom_histogram(aes(x = antal_ord))`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 3 rows containing non-finite values (`stat_bin()`).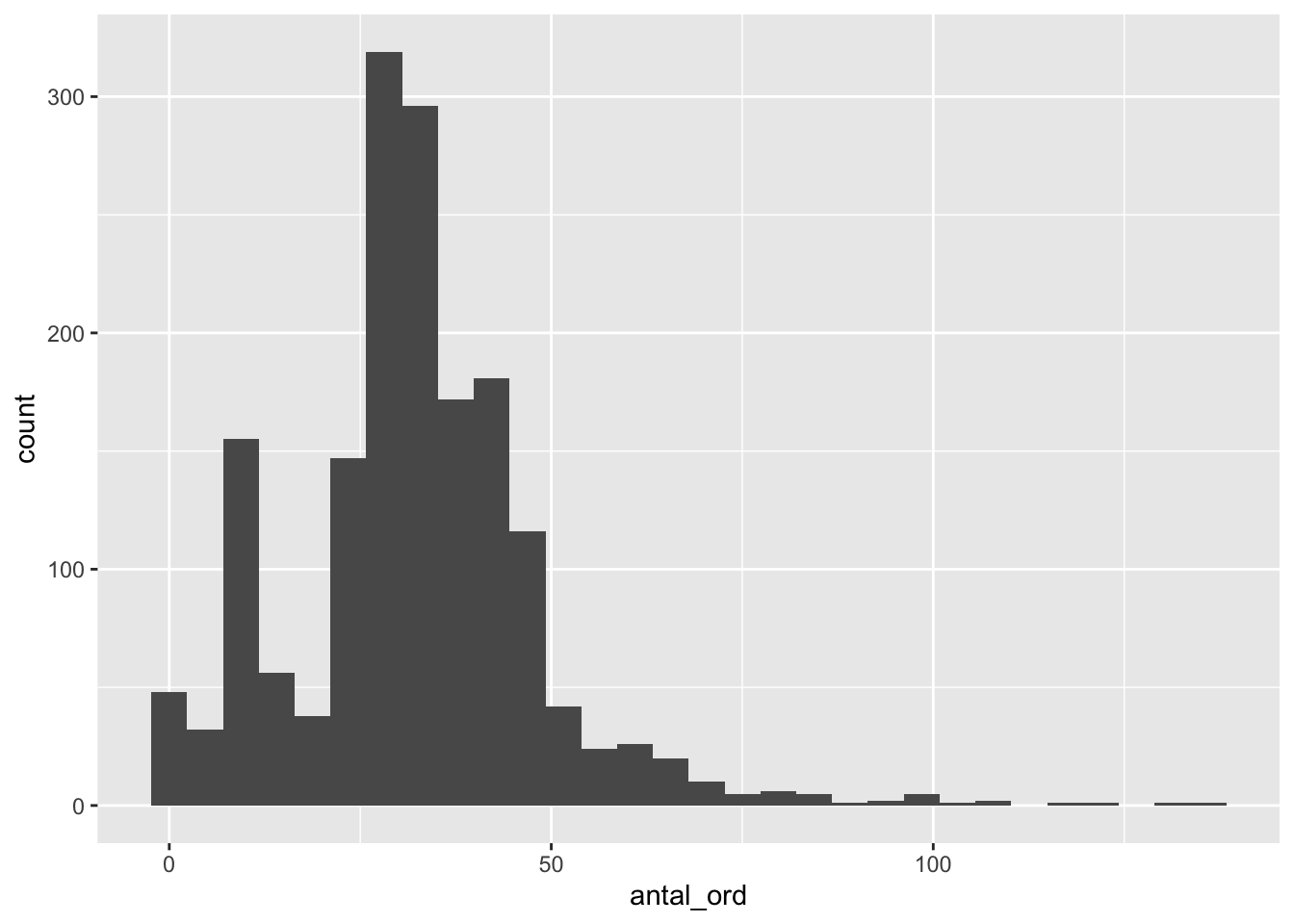
Visualiseringen antyder, at nogle signalementer er ufuldstændige. Vi kan prøve at filtrere ved at sætte en minimumstærskel for deres antal.
df <- df %>%
filter(antal_ord > 15)Hvad var det der “\\w+”? Når vi arbejder med tekststrenge arbejder vi ofte med det vi kalder “regular expression” typisk forkortet “regex”. Dette er en standardiseret måde at fange bestemte dele af tekster. Delene kan være bogstavelige - som en serie af bogstaver, tal eller tegn, der matches en for en. Men det er også muligt at fange bestemte elementer af en tekststreng uden af søge efter bestemte fraser. I koden ovenfor søger vi efter tegn der er enten bogstaver eller tal (det er det vi fanger med “w”). +tegnet fortæller, at vi leder efter noget, der matcher mindst en, men potentielt mange gange - fordi et ord jo kan indeholde mange tegn. \\tegnet fortæller R, at vi ikke leder efter et bogstaveligt w, men at dette er kode for noget andet. Str_count går derefter hvert signalement igennem og leder efter serier af tegn. Den ved, at den skal tælle, når den finder noget, der matcher kriteriet (alfanumeriske tegn). Fordi den implicit får at vide, at disse adskilles af ting, der ikke opfylder dette kriterium, får vi dermed reelt en ordoptælling.
7.3 Str_to_lower
Når vi arbejder med tekst er det ofte nyttigt at fjerne forskellen på store og små bogstaver. Dermed slipper vi for at tænke over kapitaliseringen, når vi søger. Dette gøres med funktionen str_to_lower.
df <- df %>%
mutate(Text = str_to_lower(Text))
df$Text[1:5][1] "jndkom d: 24 decbr: 1783. han er föd i kiöbenhavn, 34 aar, 65 tommer höy, er i övrigt ivalid og kan hverken gaae eller see."
[2] "jndkom d: 9d juny 1790. han er föd i kiöbenhavn, 31 aar, 58 tommer höy, stærk af skuldre og been, rundt ansigt, brune haar, og blaae øyne, meddelmaadig næse, almindelig mund, tatuert paa begge arme; ugivt"
[3] "jndkom 28 sept: 1792. han er föd i huusbye i fyen 18 aar, 62 3/4 tommer höy, proportionert af skuldre og been, blunde haar og blaae øyne, rundt ansigt, meddelmaadig næse, liden mund og et lille ar paa det venstre øyenbryn, ugivt"
[4] "jndkom 15 janv. 1793; föd i kiöbenhavn, 42 aar, 62 3/4 tommer, proportionert af skuldre og been, rundt mavert ansigt, liden næse almindelig mund, brune haar og blaae øyne, har krudpletter paa det venstre kind, gaar duknakket."
[5] "jndkom 26 febr. 1794; föd i kiöbenhavn, 21 aar, 62 1/4 tommer, proportionert af skuldre og been, rundt rödladet ansigt, sorte haar og brunt øyne, maadelig næse, stor mund." Nu findes der ingen store bogstaver i vores tekst. En grund til, at det kan være smart at gøre alting småt er, at det gør det lettere at tænke igennem forskellige variationer. Reelt gør vi jo computeren i stand til at forstå, at “København” og “københavn” er det samme.
7.4 Str_detect
Når vi arbejder med tekst kan vi skabe nye kolonner ved at tjekke efter om en bestemt tekststreng optræder. Det lyder simpelt, men er ekstremt nyttigt. Ofte vil vi som historikere være interesserede i, at skabe en variabel, der indikerer et eller andet om vores materiale. Og ofte vil vi kunne tænke os til formuleringer, der antyder at et eller andet gør sig gældende, fordi bestemte fraser optræder.
df %>%
mutate(Text = str_to_lower(Text)) %>%
mutate(Vorte = str_detect(Text, "vorte"),
Københavner = str_detect(Text, "k(i|j)öbenh")) %>%
head()# A tibble: 6 × 4
Text antal…¹ Vorte Køben…²
<chr> <int> <lgl> <lgl>
1 jndkom d: 24 decbr: 1783. han er föd i kiöbenhavn, 34 a… 25 FALSE TRUE
2 jndkom d: 9d juny 1790. han er föd i kiöbenhavn, 31 aar… 36 FALSE TRUE
3 jndkom 28 sept: 1792. han er föd i huusbye i fyen 18 aa… 43 FALSE FALSE
4 jndkom 15 janv. 1793; föd i kiöbenhavn, 42 aar, 62 3/4 … 38 FALSE TRUE
5 jndkom 26 febr. 1794; föd i kiöbenhavn, 21 aar, 62 1/4 … 30 FALSE TRUE
6 jndkom 23 july 1794; föd i haslev i siælland, 36 aar. 6… 43 TRUE FALSE
# … with abbreviated variable names ¹antal_ord, ²KøbenhavnerFordi vi har brugt Str_detect som del af mutate, skabes der nye kolonner. Output fra str_detect er en logisk kategori, der skelner mellem TRUE og FALSE. Hvis vi f.eks. vil kigge på korrelation, kan disse let konverteres til numeriske værdier: 1 og 0.
df <- df %>%
mutate(fyldig = as.numeric(str_detect(Text, "fyldig")),
stærk = as.numeric(str_detect(Text, "stærk")))
cor.test(df$fyldig, df$stærk)
Pearson's product-moment correlation
data: df$fyldig and df$stærk
t = 7.2556, df = 1429, p-value = 6.536e-13
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.1380237 0.2379902
sample estimates:
cor
0.1884952 7.4.1 Filtrering med str_detect
Str_detect kan også bruges til at filtrere. Filter-funktionen antager, at vi leder efter matches, og filtrerer automatisk de rækker væk, hvor str_detect resulterer i værdien FALSE. Nedenfor vil vi kun se observationer, der indeholder omtale af københavn og vorter.
df %>%
mutate(Text = str_to_lower(Text)) %>%
filter(str_detect(Text, "k(i|j)öbenh") & str_detect(Text, "vorte"))# A tibble: 6 × 4
Text antal…¹ fyldig stærk
<chr> <int> <dbl> <dbl>
1 jndkom d: 7 april 1808, föd i kiöbenhavn, 26 aar, 61 tom… 37 0 1
2 jndkom d: 12 novbr. 1808, föd i kiöbenhavn, 29 aar, 63 1… 37 0 0
3 jndkom 3 octbr 1810, föd i kiöbenhavn, 41 aar, 63 1/4 t … 43 0 0
4 jndkom den 18de marti 1822 paa 5 aar, föd i kiöbenhavn 2… 41 0 0
5 overfört fra rendsborg den 22 april 1824. jndkom 18de ma… 51 0 0
6 jndkom den 26de may 1824 paa livstid han er 35 aar gamel… 90 0 0
# … with abbreviated variable name ¹antal_ord7.5 Str_extract
Hvor str_detect laver en test på hvorvidt en bestemt term optræder, kan funktionen str_extract bruges til at hive en bestemt del af en streng ud.
Med regex kan vi desuden fange tekststrenge, der kommer før eller efter noget andet. I denne kontekst kan vi f.eks. bruge dette til at rekonstruere en dato for fangens ankomst, der i næsten alle tilfælde omtales først i signalementet.
#Hiv det første tal med 4 ciffre ud
df <- df %>%
mutate(År = str_extract(Text, "(\\d){4}"))# Hiv det første tal ud
df <- df %>%
mutate(Dag = str_extract(Text,
"(\\d+)"))#Hiv ordet før årstallet ud
df <- df %>%
mutate(Måned = str_extract(Text,
"\\S+(?= (\\d){4})"))Måneder optræder som tekst, men kan vha. en kombination af if_else og str_extract konverteres.
# Måneder til måneder
df <- df %>%
mutate(Måned_tal = if_else(str_detect(Måned, "an(u|v)"), 1,
if_else(str_detect(Måned, "feb"), 2,
if_else(str_detect(Måned, "mar"), 3,
if_else(str_detect(Måned, "apr"), 4,
if_else(str_detect(Måned, "ma(i|y|j)"), 5,
if_else(str_detect(Måned, "jun"), 6,
if_else(str_detect(Måned, "jul"), 7,
if_else(str_detect(Måned, "aug"), 8,
if_else(str_detect(Måned, "sep"), 9,
if_else(str_detect(Måned, "o(c|k)t"), 10,
if_else(str_detect(Måned, "no"), 11,
if_else(str_detect(Måned, "dec"), 12, NA)))))))))))))Nu kan vi skabe en egentlig dato.
library(lubridate)
Attaching package: 'lubridate'The following objects are masked from 'package:base':
date, intersect, setdiff, uniondf <- df %>%
mutate(dato = paste(Dag, Måned_tal, År, sep = "-"),
dato = dmy(dato))Warning: There was 1 warning in `mutate()`.
ℹ In argument: `dato = dmy(dato)`.
Caused by warning:
! 32 failed to parse.Lad os se, hvordan signalementerne fordeler sig over tid.
ggplot(df) +
geom_histogram(aes(x = dato), binwidth = 365)Warning: Removed 32 rows containing non-finite values (`stat_bin()`).
Fordi signalementerne indeholder en række ganske standardiserede formuleringer kan vi også bruge den til at finde de ord, der knytter sig specifikt til andre. Lad os prøve at se på ordene, der kommer før “haar”.
# Hiv et ord ud før et andet ord
df <- df %>%
mutate(Før_hår = str_extract(Text,
"\\w+(?= (af |)haar)"))
df %>%
group_by(Før_hår) %>%
summarise(antal = n()) %>%
arrange(desc(antal))# A tibble: 118 × 2
Før_hår antal
<chr> <int>
1 sorte 191
2 blonde 180
3 brune 125
4 sort 95
5 blondt 71
6 mörkt 63
7 bruunt 61
8 blond 56
9 <NA> 50
10 mörke 44
# … with 108 more rowsSignalementerne har også oplysninger om fangernes fødesteder. Disse optræder ligeledes i en bestemt formulering med få variationer og kan derfor trækkes ud ved at fange det, der kommer efter en bestemt formulering.
# Hiv et ord ud efter en serie af ord med variationer
df <- df %>%
mutate(Fødested = str_extract(Text,
"(?<=(föd(t|) (paa|i)) )\\w+"))
df %>%
group_by(Fødested) %>%
summarise(antal = n()) %>%
arrange(desc(antal))# A tibble: 537 × 2
Fødested antal
<chr> <int>
1 <NA> 318
2 kiöbenhavn 124
3 kjöbenhavn 60
4 jylland 43
5 norge 32
6 sverrig 25
7 khn 20
8 sjelland 20
9 holsteen 14
10 khavn 14
# … with 527 more rows7.6 Frekvenser over tid
Ved at kombinere nogle af de teknikker, der er beskrevet ovenfor, kan vi prøve at se på hvordan forskellige termer optræder over tid.
Dette gøres ved at udregnes et totalt antal signalementer pr. år, der bruges til at udregne en ratio for, hvor stor en del af signalementerne i et givent år indeholder en bestemt term.
df_frekvens <- df %>%
group_by(År) %>%
mutate(antal_sig_år = n(),
antal_term_1 = as.numeric(str_detect(Text, "kopa")),
antal_term_2 = as.numeric(str_detect(Text, " a(hr|r)"))) %>%
summarize(ratio_1 = sum(antal_term_1 / antal_sig_år),
ratio_2 = sum(antal_term_2 / antal_sig_år)) %>%
filter(År > 1806) %>%
add_row(År = "1816") %>%
pivot_longer(cols = 2:3, names_to = "Term", values_to = "Frekvens")
ggplot(df_frekvens) +
geom_line(aes(x = as.numeric(År), y = Frekvens, linetype = Term))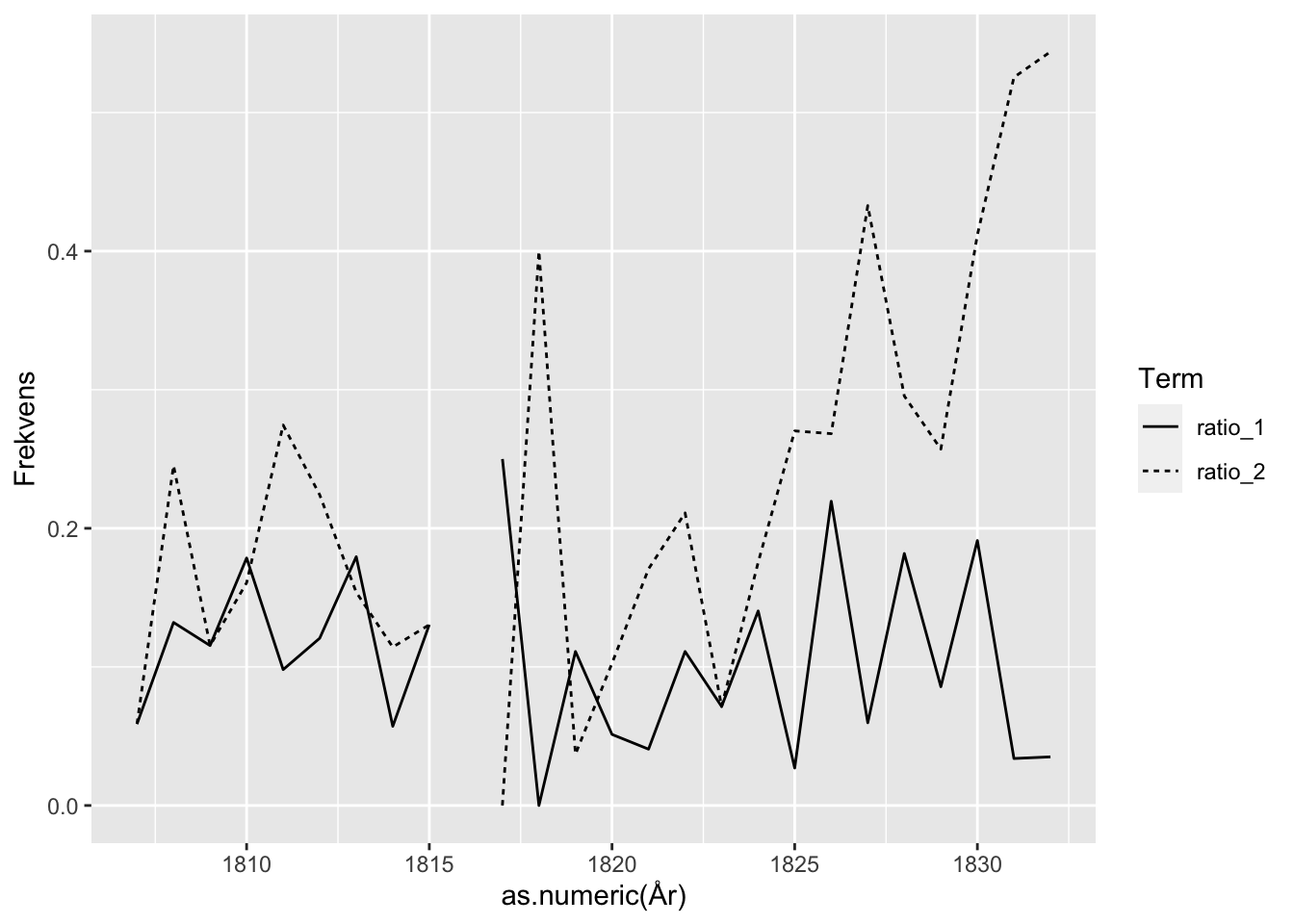
R gør os på denne måde i stand til at begynde at stille kvalificerede spørgsmål til vores tekster. Ofte kan sådanne udforskninger være nyttige i den fase, hvor vi forsøger at formulere, hvad det virkelig er, vi interesserer os for. Det kan således tænkes som en del af den proces, hvor historikeren stiller spørgsmål.