library(tidygraph)
library(ggraph)
library(widyr)
library(tidytext)
library(tidyverse)
library(readxl)
library(quanteda)9 Visuel udforskning af sammenhænge i tekster
Dette kapitel handler om at udforske sammenhænge imellem ord i tekster. I modsætning til senere kapitler, hvor vi bruger forskellige algoritmer til at undersøge og klassificere tekst, bruger vi her teknikker, der kan synliggøre mønstre i materialet visuelt. Dette kan være ekstremt nyttigt som led i en eksplorativ dataanalyse - den proces hvor vi genererer spørgsmål om vores kilder.1
9.1 Setup
For at komme igang skal vi loade data ind. Dataene vi bruger er avisannoncer, hvor mennesker efterlyses - typisk af en arbejdsgiver. Annoncerne stammer fra Københavns Adresseavis og er et sample på 925 annoncer fra de sidste to årtier af 1700-tallet. Det er lavet af Anders Birkemose.
df <- read_excel("data/sample.xlsx") %>% select(Text, ID)
stopord <- read_excel("data/stopord2.xlsx")
head(df)# A tibble: 6 × 2
Text ID
<chr> <chr>
1 Da Jørgen Jensen, fød i Rønne paa Bornholm, der som kok var forhyret ti… ID-1
2 Da min Tienestepige, navnlig Jacobine, uden Aarsag er bortgaaet; saa ad… ID-2
3 Da en Pige haver fæstet sig i min Tieneste, og leveret mig hendes Skuds… ID-3
4 Da min Læredreng, navnlig Peter Ridel, er i Søndags Middag undvigt af s… ID-4
5 Da 2 svenske Drenge, den eene John, 16 Aar, undersætsig, klædt i en hvi… ID-5
6 Den 30 December er Margarete Rebecca M. hemmelig undvigt fra hendes Log… ID-6 Vi starter med at rydde lidt op i vores tekst. Det kan godt betale sig, at vende tilbage til dette punkt senere og eksperimentere med forskellige erstatninger.
df$Text <- str_to_lower(df$Text)
df$Text <- str_replace_all(df$Text, c("uu" = "u",
"ii" = "i",
"ee" = "e"))Vi tokeniserer først på ordniveau. Vi skal nemlig bruge sådan en datastruktur flere gange undervejs.
Token_df <- df %>%
unnest_tokens(word, Text)
head(Token_df)# A tibble: 6 × 2
ID word
<chr> <chr>
1 ID-1 da
2 ID-1 jørgen
3 ID-1 jensen
4 ID-1 fød
5 ID-1 i
6 ID-1 rønne Vi fjerner stopord og alt, der indeholder tal.
Token_df <- Token_df %>%
anti_join(stopord) %>%
filter(!str_detect(word, "[0-9]+"))Vi laver herefter en optælling, så vi kan se de mest hyppige ord. Dette er både for at få en rå fornemmelse for, hvad der dominerer vores data og fordi vi skal bruge denne oversigt senere.
Token_counts <- Token_df %>%
count(word, sort = TRUE) %>%
rename(name = word)
head(Token_counts)# A tibble: 6 × 2
name n
<chr> <int>
1 mig 635
2 han 634
3 min 500
4 aar 396
5 hans 379
6 gammel 3669.2 Bigrams
Målet er at gøre sammenhænge imellem ord i vores korpus læselige uden at læse teksterne på traditionel vis. Vi kigger først på bigrams. Et bigram er en direkte forbindelse imellem to ord, hvor det ene følger efter det andet. Ved at justere på værdien “n” i unnest_tokens(), kan vi også få andre enheder, f.eks. bidder af 3 ord - såkaldte trigrams. Sådanne enheder giver et simpelt og intuitivt indblik i, hvad en tekst indeholder.
Text_bigrams <- df %>%
unnest_tokens(bigram, Text, token = "ngrams", n = 2)Vi tæller de mest hyppige bigrams.
Bigram_count <- Text_bigrams %>%
count(bigram, sort = TRUE)
head(Bigram_count)# A tibble: 6 × 2
bigram n
<chr> <int>
1 aar gammel 257
2 da min 252
3 i en 242
4 klædt i 221
5 huse eller 200
6 og enhver 198Vores kolonne med ordforbindelser indeholder de ord vi filtrerede fra som stopord i vores oversigt over enkelte ord. Vi vil også gerne slippe for dem her. For at vi kan fjerne bigrams, der indeholder stopord, skal vi dog først splitte vores bigrams op, så hvert ord bor i sin egen kolonne.
Bigrams_separated <- Text_bigrams %>%
separate(bigram, c("word1", "word2"), sep = " ")Vi filtrerer rækker, der indeholder stopord eller tal ud fra hver kolonne.
Bigrams_separated <- Bigrams_separated %>%
anti_join(stopord, by = c("word1" = "word")) %>%
anti_join(stopord, by = c("word2" = "word")) %>%
filter(!str_detect(word1, "[0-9]+")) %>%
filter(!str_detect(word2, "[0-9]+"))Vi laver en ny optælling på vores opdaterede datasæt.
Bigram_count <- Bigrams_separated %>%
count(word1, word2, sort = TRUE)
head(Bigram_count)# A tibble: 6 × 3
word1 word2 n
<chr> <chr> <int>
1 aar gammel 257
2 hans opholdssted 151
3 min læredreng 144
4 opholdssted tilkiende 135
5 mit navn 101
6 mig hans 89Lad os prøve at visualisere teksten som et netværk af ordforbindelser.
For at gøre det laver vi først et graf-objekt. Denne handling bruger vores oversigt over bigrams og deres antal til at danne et objekt, der både indeholder en dataframe over de enkelte ord (nodes) og en der lister forbindelser (edges). Slice_max-funktionen filtrerer på de højeste værdier - i dette tilfælde de bigrams, der har den højeste værdi i kolonnen “n” - mao. dem, som er hyppigst. Ved at vælge en større værdi kan vi få mere af vores data med, men grafen bliver også sværere at læse. Nu vi er igang, føjer vi også vores oprindelige optælling af enkelte ord-tokens på graf-objektets oversigt over ord. Så kan vi bruge den oplysning i vores visualisering.
Bigram_graph <- Bigram_count %>%
slice_max(n, n = 50) %>%
as_tbl_graph() %>%
activate(nodes) %>%
left_join(Token_counts, by = "name")Nu er vi klar til at visualisere bigram-forbindelserne som et netværk.
a <- grid::arrow(type = "open", length = unit(.10, "inches"))
ggraph(Bigram_graph, layout = "fr") +
geom_node_point(alpha = 0.3,
color = "#CC7800")+
geom_edge_link(aes(width = n),
alpha = 0.3,
show.legend = FALSE,
arrow = a,
color = "#CC7800") +
geom_node_text(aes(label = name, size = n),
show.legend = FALSE,
color = "black",
repel = TRUE) +
scale_edge_width_continuous(range = c(0.3, 2)) +
scale_size_continuous(range = c(2, 5)) +
theme_void() +
labs(caption = "Bigrams i efterlysningsannoncer.\nStørrelse angiver hyppighed.\nAnnoncer fra København, 1780-1800.")Warning: Using the `size` aesthetic in this geom was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` in the `default_aes` field and elsewhere instead.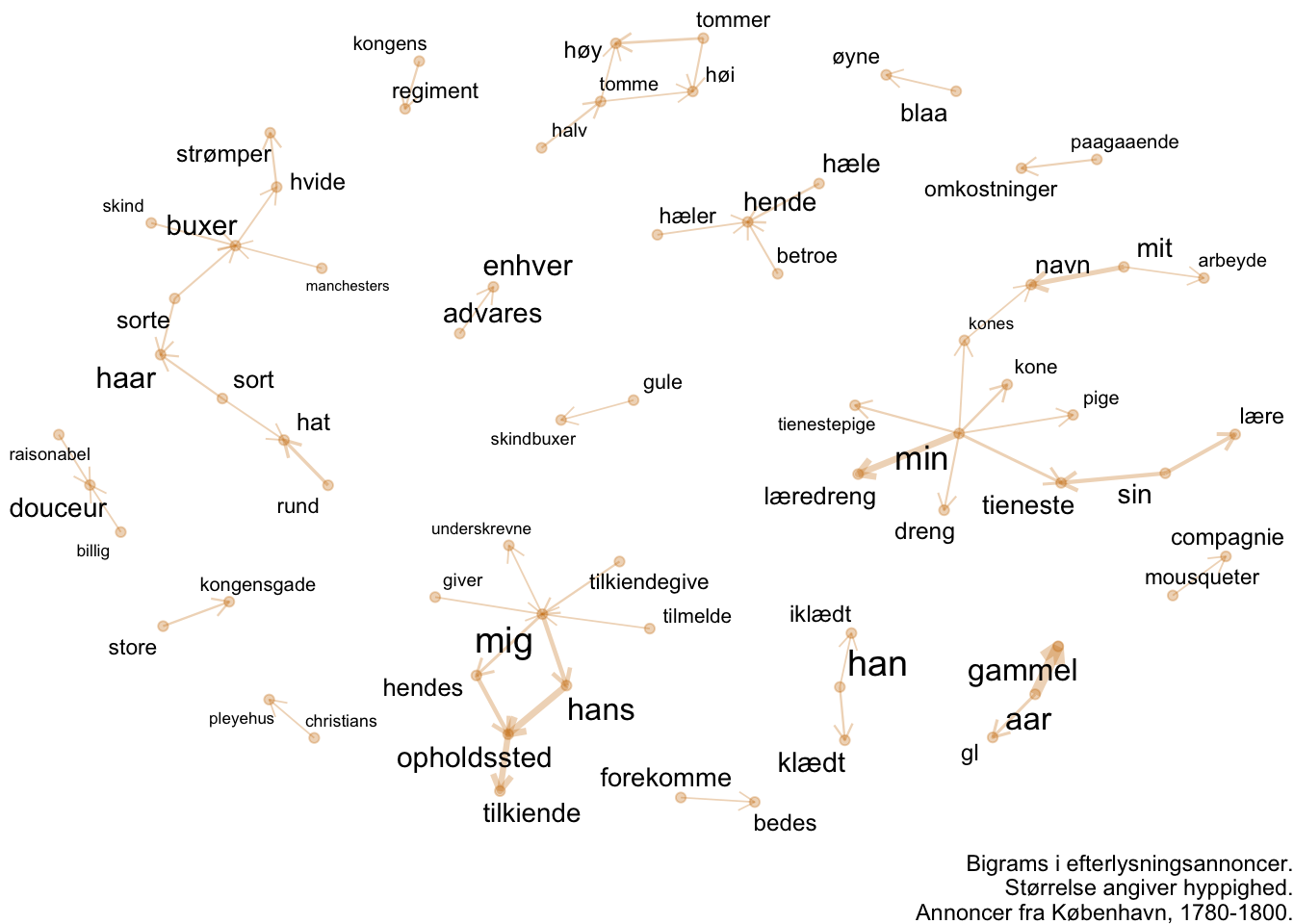
Bigrams giver os en intuitiv måde at få et indtryk af faste vendinger i et stort materiale. Det kan bruges både som kommunikation til vores læser og som del af vores undersøgelsesproces.
9.3 Parvise optællinger
Men hvad med andre sammenhænge i en tekst? F.eks. at to ord optræder i samme tekst, men ikke i direkte forlængelse? Dette kan vi gøre ved at lave en parvis optælling, hvor vi ser hvor ofte ord optræder i samme tekst. Dette gør vi nedenfor, hvor vi igen filtrerer på hyppighed af forbindelser og igen knytter vores oprindelige optælling af ord-tokens på vores graf-objekt.
word_pairs <- Token_df %>%
pairwise_count(word, ID, sort = TRUE) %>%
filter(item1 > item2)
pairwise_graph <- word_pairs %>%
slice_max(n, n = 150) %>%
as_tbl_graph() %>%
activate(nodes) %>%
left_join(Token_counts, by = "name")Lad os visualisere det på samme måde som vi visualiserede bigrams!
ggraph(pairwise_graph, layout = "fr") +
geom_node_point(alpha = 0.3,
color = "#CC7800")+
geom_edge_link(aes(width = n),
alpha = 0.3,
show.legend = FALSE,
color = "#CC7800") +
geom_node_text(aes(label = name, size = n),
show.legend = FALSE,
color = "black",
repel = TRUE) +
scale_edge_width_continuous(range = c(0.3, 2)) +
scale_size_continuous(range = c(2, 5)) +
theme_void() +
labs(caption = "Ord, der optræder i samme efterlysningsannonce.\nStørrelse angiver hyppighed.\nAnnoncer fra København, 1780-1800.")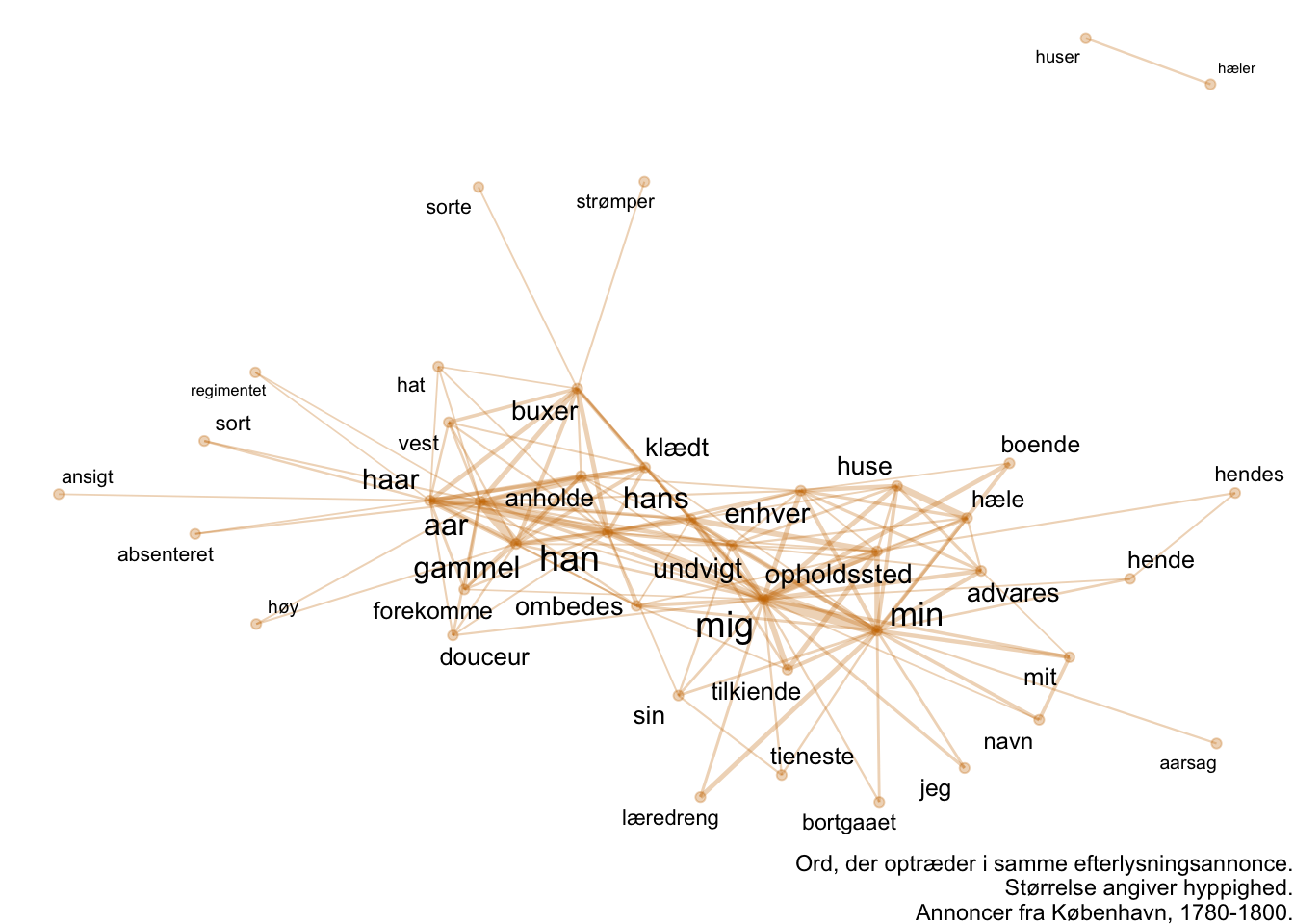
Den var måske ikke helt så nyttig. Visualiseringen er lidt en hårbold, der primært kommunikerer, at de hyppige ord, pudsigt nok, også ofte optræder sammen. Det er ikke særligt overraskende, heller ikke selvom vi allerede har filtreret stopord fra. Hvad sker der, hvis vi bare kigger på en tabel over hyppighed?
head(word_pairs, 25)# A tibble: 25 × 3
item1 item2 n
<chr> <chr> <dbl>
1 min mig 279
2 gammel aar 255
3 haar aar 204
4 opholdssted mig 196
5 huse hæle 190
6 mig hans 186
7 han aar 179
8 mig han 176
9 haar gammel 166
10 tilkiende mig 165
# … with 15 more rowsDet var måske straks mere interessant. Her kan vi begynde at stille spørgsmål. Eksempelvis: Hvorfor optræder “haar” og “aar” sammen? Det har ikke umiddelbart noget med hinanden at gøre? Men måske har det alligevel.
9.4 Optællinger indenfor vinduer
Hvor den rå optælling måske ikke fortæller os så meget om andet end, at hyppige ord også har mange sammenfald, kan vi få et andet blik på teksten ved at inddele denne i vinduer.
df_windowed_tokenized <- kwic(tokens(df$Text,
remove_punct = TRUE,
remove_numbers = TRUE),
window = 5,
pattern = "\\w+",
valuetype = "regex") %>%
as.data.frame() %>%
mutate(Text = paste(pre, keyword, post, sep = " ")) %>%
rownames_to_column(var = "ID") %>%
unnest_tokens(word, Text) %>%
anti_join(stopord) %>%
filter(!str_detect(word, "[0-9]+"))
df_pairwise_count <- df_windowed_tokenized %>%
pairwise_count(word, ID)
df_pairwise_count <- df_pairwise_count %>%
filter(item1 > item2) %>%
slice_max(n, n = 500)
df_pairwise_count_graph <- df_pairwise_count %>%
as_tbl_graph(directed = FALSE) %>%
activate(nodes) %>%
left_join(Token_counts)
ggraph(df_pairwise_count_graph, layout = "fr") +
geom_node_point(aes(size = n), alpha = 0.3, colour = "#CC7800") +
geom_edge_link(aes(width = n), alpha = 0.3, colour = "#CC7800") +
geom_node_text(aes(label = name, size = n)) +
scale_size_continuous(range = c(1, 3)) +
scale_edge_width_continuous(range = c(0.2, 2)) +
theme_void() +
theme(legend.position = "none")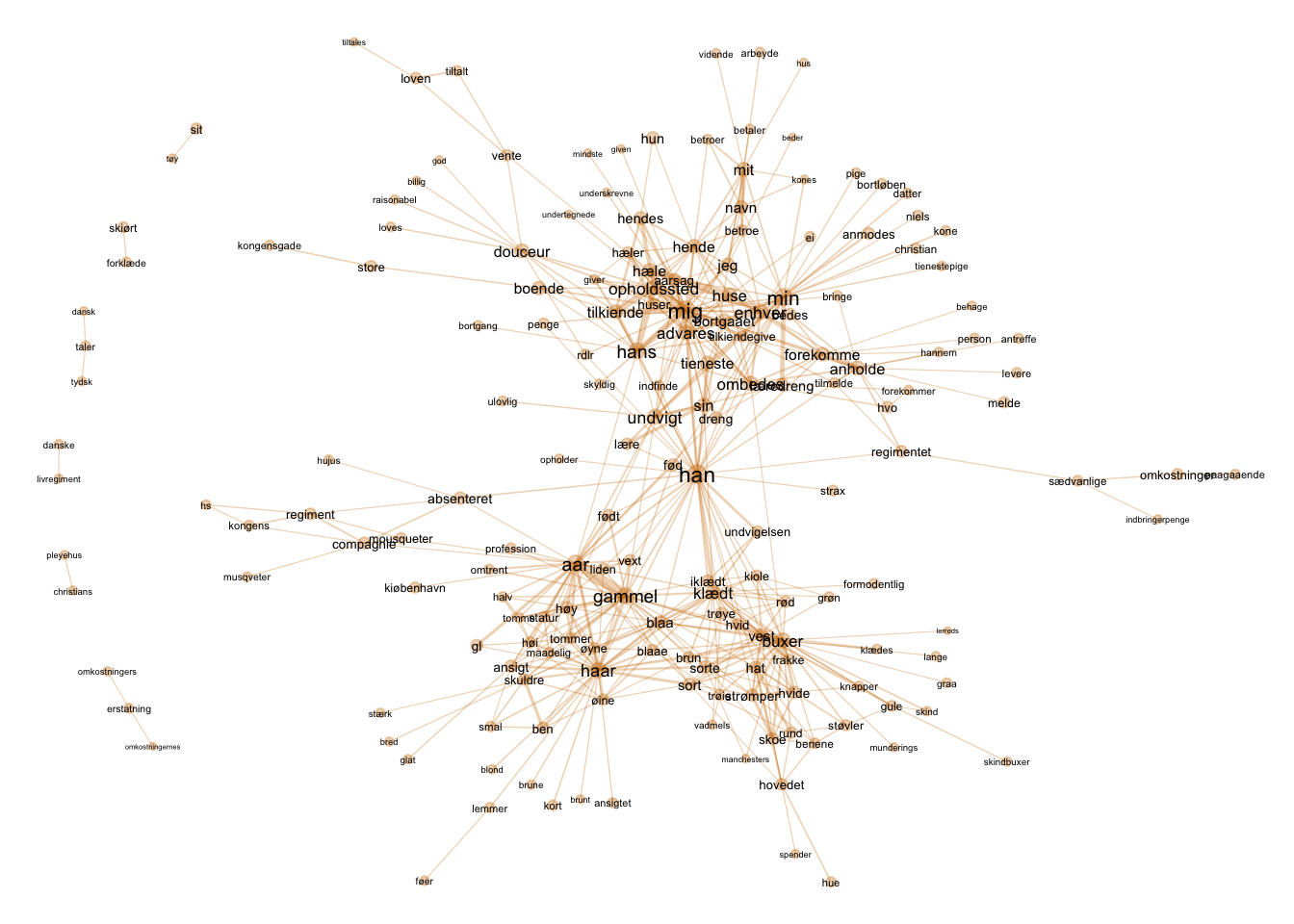
Grafen antyder en kløft i dataene - en samling af ord knytter sig til “mig” imens en anden serie af ord knytter sig til udseende. I sidstnævnte finder vi også “aar”. I midten finder vi “han”, der således fremstår som et centralt ord. Dette er måske ikke overraskende, da mænd fylder noget mere end kvinder i materialet.
9.5 Korrelationer imellem ord
Den struktur vi aner ovenfor bliver vi måske klogere på, hvis vi i stedet for blot at tælle, kigger på korrelationen imellem ord. Her optæller vi ikke bare antallet af sammenfald, men en koefficient for korrelationener imellem ords frekvenser. Og vi gør det imellem hvert ordpar. Koefficienten kan være positiv, hvilket antyder, at ordene gerne optræder sammen. Den kan også være negativ, hvilket antyder at ordene typisk optræder hver for sig.
Tidligere i denne bog udregnede vi i en anden kontekst Pearsons korrelationskoefficient. Denne egner sig bedst til kontinuerte tal. Hvis vi vil undersøge korrelation imellem binære data (hvilket vi får, når vi spørger om et ord optræder eller ej) kan vi i stedet bruge den såkaldte phi-koefficient, der giver en score, der tolkes på samme måde som Pearsons. Tilsvarende den parvise optælling ovenfor, findes også funktionen pairwise_cor(), der udregner en sådan score imellem hvert potentielt par i et tokeniseret korpus. Da der hurtigt bliver rigtigt mange ordpar (alle potentielle kombinationer af ord undersøges), kan det være en fordel at filtrere forinden, så ord, der optræder sjældent ikke regnes med.
word_cors <- Token_df %>%
group_by(word) %>%
filter(n() >= 10) %>%
pairwise_cor(word, ID, sort = TRUE)
head(word_cors, 10)# A tibble: 10 × 3
item1 item2 correlation
<chr> <chr> <dbl>
1 hæler huser 0.908
2 huser hæler 0.908
3 hæle huse 0.856
4 huse hæle 0.856
5 pleyehus christians 0.828
6 christians pleyehus 0.828
7 bestalter klim 0.805
8 klim bestalter 0.805
9 ben skuldre 0.793
10 skuldre ben 0.793Hvad korrelerer et bestemt ord med? Prøv at skifte ud på termerne i filteret!
word_cors %>%
filter(item1 == "tienestepige" | item1 == "regiment") %>%
group_by(item1) %>%
slice_max(correlation, n = 15) %>%
ungroup() %>%
mutate(item2 = reorder(item2, correlation)) %>%
ggplot(aes(x = item2, y = correlation)) +
geom_bar(stat = "identity") +
facet_wrap(~ item1, scales = "free") +
coord_flip()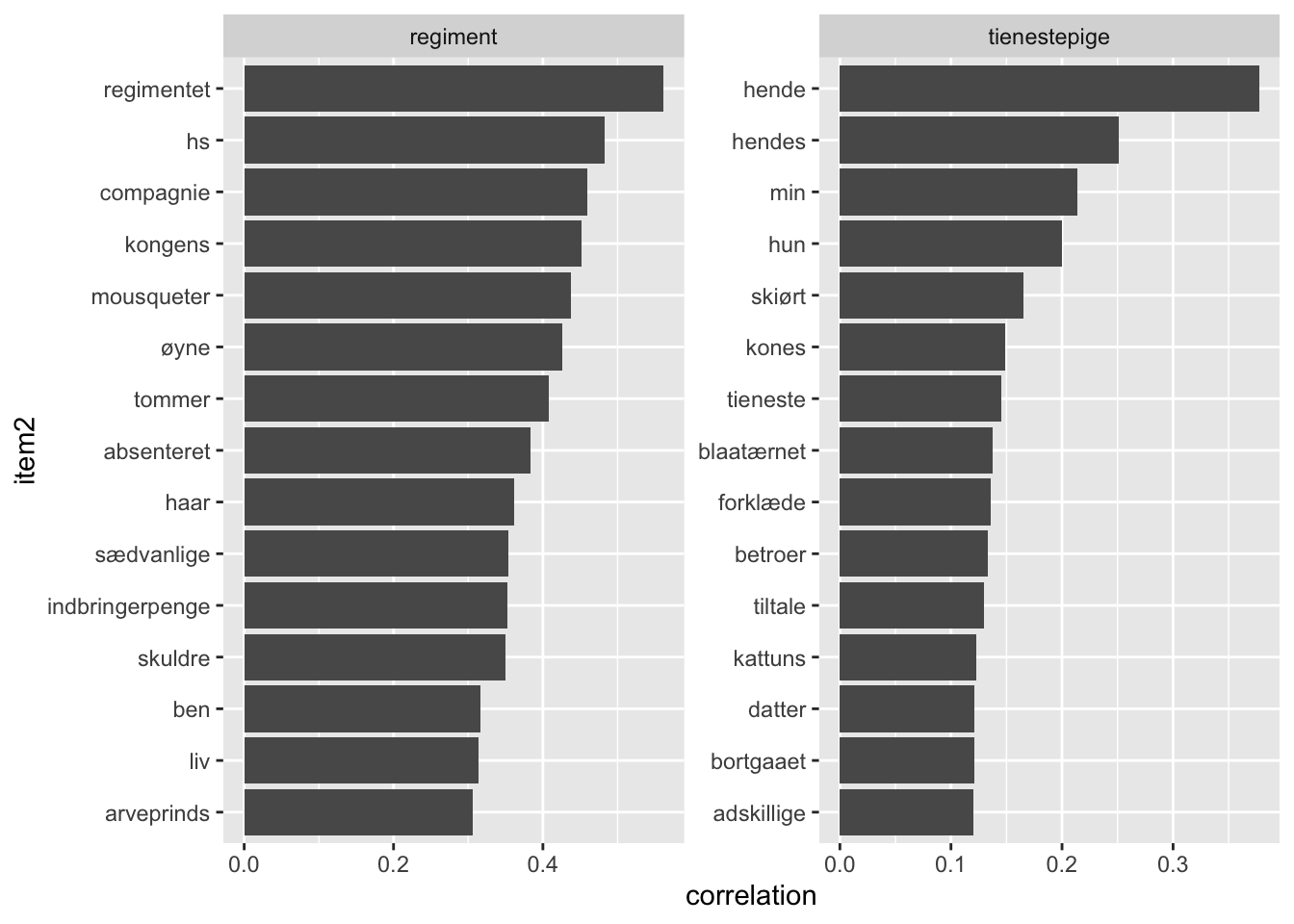
Her får vi et værktøj til at gå i dybden med enkelte termer. En anden tilgang ville være, at kigge på hyppige korrelationer generelt. For at visualisere både positive og negative korrelationer kan vi lave et heatmap. Nedenfor udregnes korrelationerne imellem de hyppigste ord i vores data og visualiseres.
word_cors_top <- Token_df %>%
group_by(word) %>%
filter(n() >= 200) %>%
pairwise_cor(word, ID, sort = TRUE)
word_cors_top <- word_cors_top %>%
filter(item1 > item2)
ggplot(word_cors_top, aes(item1, item2, fill = correlation)) +
geom_tile() +
scale_fill_gradient2(low = "red", high = "blue", mid = "white",
midpoint = 0) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust= 1)) +
coord_fixed()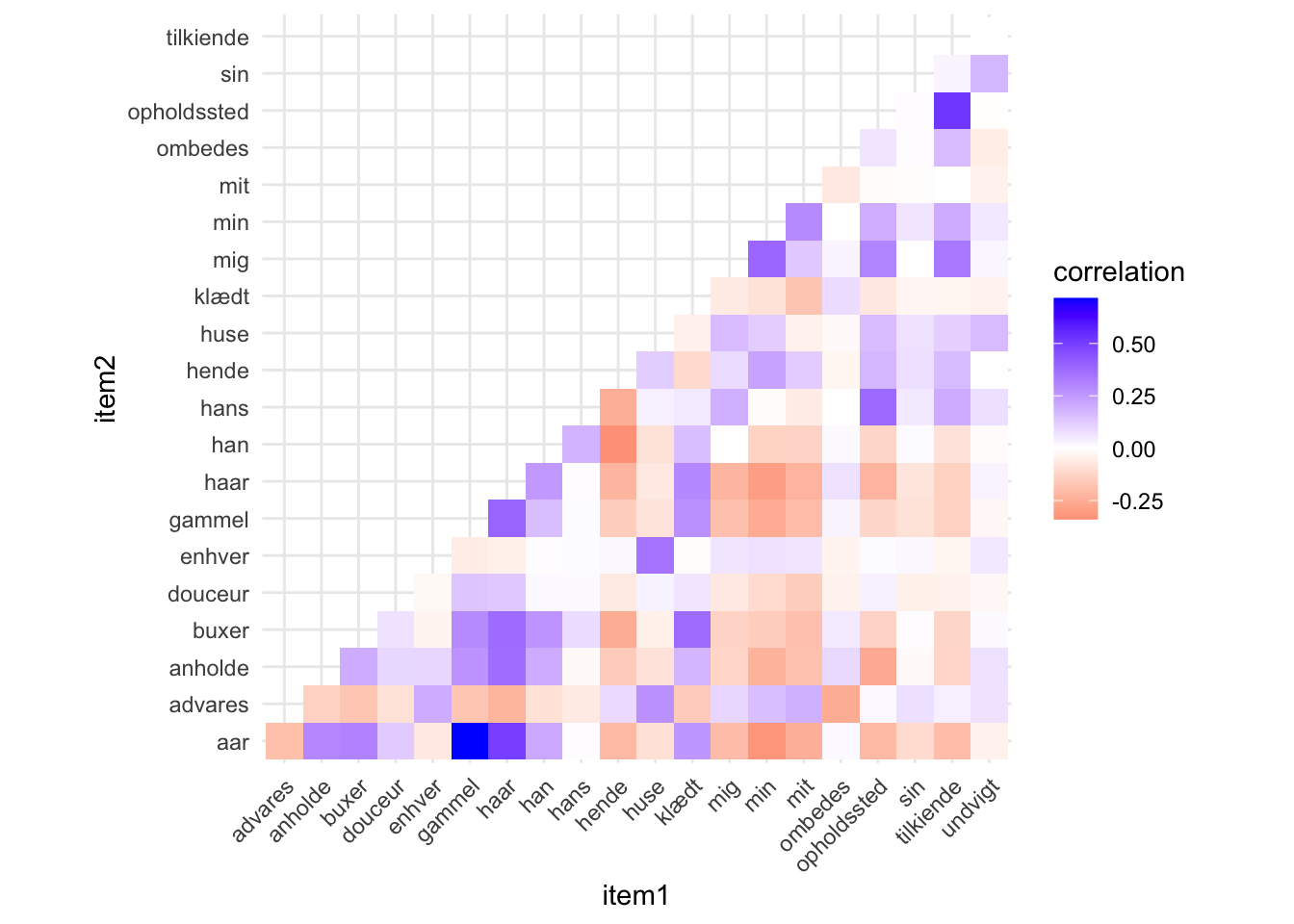
Visualiseringen antyder både faste vendinger, men også at genren er kønnet. “Hende” har en negativ korrelation med mange af de termer, som “han” korrelerer med. Vi fornemmer også mønstre, der knytter sig til “mig”, “min” og “mit”. Disse korrelerer f.eks. sjældent med “haar”.
Som visualisering er matricen ovenfor fed, fordi vi kan fange både positive og negative korrelationer. Men den bliver uoverskuelig, hvis for mange termer er med og vi har svært ved at se mønstre. Som netværksvisualisering kan vi kun se på de positive korrelationer, men kan til gengæld lettere se mønstre. Lad os prøve.
word_cors %>%
slice_max(correlation, n = 250) %>%
as_tbl_graph() %>%
activate(nodes) %>%
left_join(Token_counts, by = "name") %>%
ggraph(layout = "fr") +
geom_node_point(alpha = 0.3,
color = "#CC7800")+
geom_edge_link(aes(width = correlation),
alpha = 0.3,
show.legend = FALSE,
color = "#CC7800") +
geom_node_text(aes(label = name, size = n),
show.legend = FALSE,
color = "black",
repel = TRUE) +
scale_edge_width_continuous(range = c(0.3, 2)) +
scale_size_continuous(range = c(2, 5)) +
theme_void() +
labs(caption = "De 250 højeste korrelationskoefficienter imellem ordpar i datasættet.\nStørrelse angiver hyppighed.\nAnnoncer fra København, 1780-1800.")
Her fornemmer vi, at sproget om militært personale er fasttømtret. Til gengæld har vi svært ved at se større mønstre i resten. Det kan vi måske råde bod på, ved at filtrere på både ordets hyppighed og korrelation samtidig og ved at se et større slice af korrelationer.
word_cors_top_alt <- Token_df %>%
group_by(word) %>%
filter(n() >= 100) %>%
pairwise_cor(word, ID, sort = TRUE)
word_cors_top_alt %>%
slice_max(correlation, n = 1000) %>%
as_tbl_graph() %>%
activate(nodes) %>%
left_join(Token_counts, by = "name") %>%
ggraph(layout = "fr") +
geom_node_point(alpha = 0.3,
color = "#CC7800")+
geom_edge_link(aes(width = correlation),
alpha = 0.3,
show.legend = FALSE,
color = "#CC7800") +
geom_node_text(aes(label = name, size = n),
show.legend = FALSE,
color = "black",
repel = TRUE) +
scale_edge_width_continuous(range = c(0.3, 2)) +
scale_size_continuous(range = c(2, 5)) +
theme_void() +
labs(caption = "Hyppige korrelationer imellem hyppige ord.\nStørrelse angiver hyppighed.\nAnnoncer fra København, 1780-1800.")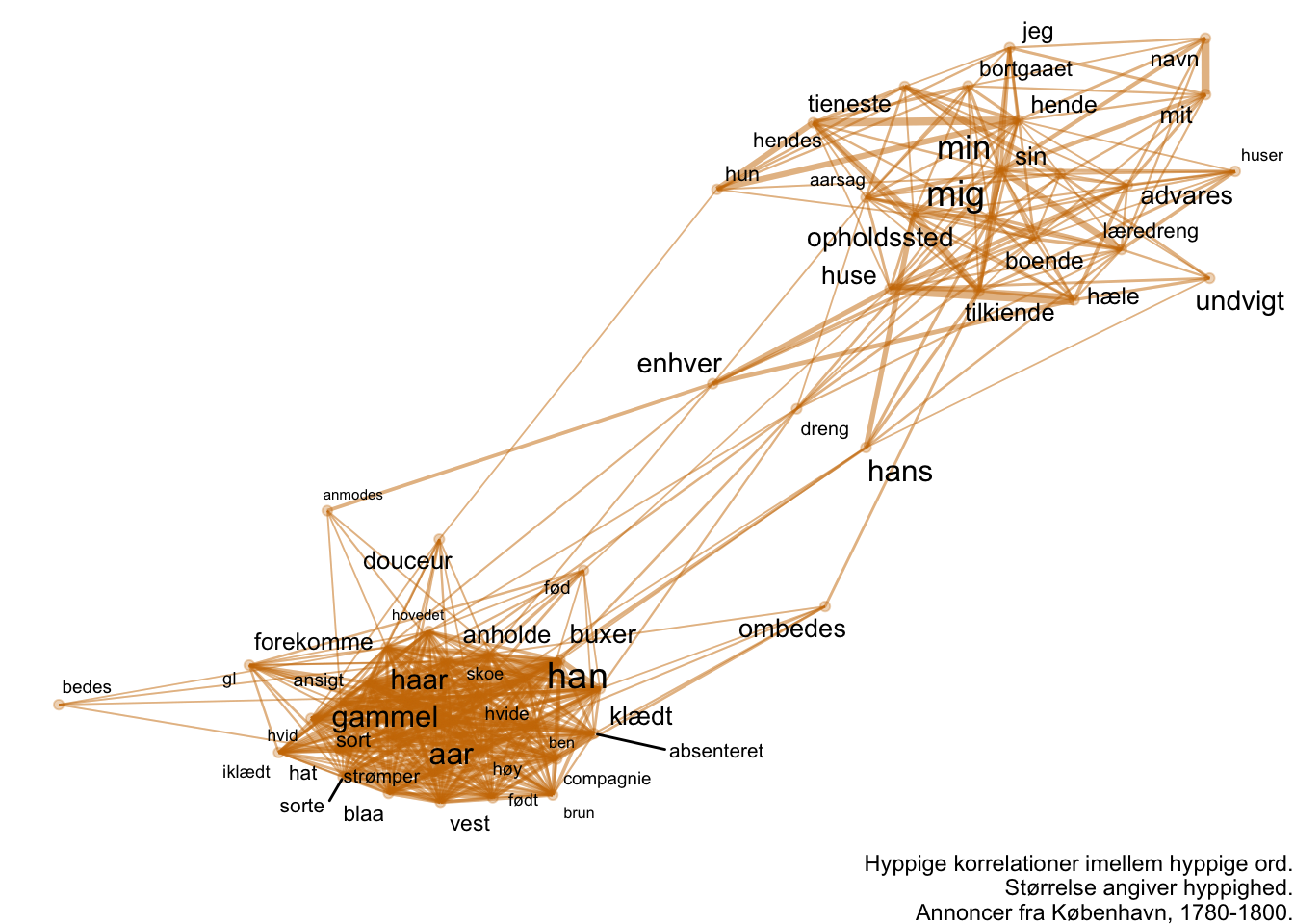
Her ser vi konturerne af to temaer eller genrer i materialet. Et fasttømret sprog om folks udseende, der handler om at anholde mennesker beskrevet på disse kropslige kendetegn. Ofte kommer disse fra institutioner (regimenter, flåden, fængsler) og disse mennesker kender man derfor alderen på, så dette forklarer sammenhængen imellem “haar” og “aar” fra tidligere. Bemærk placeringen af orden “han”, der ikke længere er en bro i materialet, som det var tilfældet i graferne, der blot talte sammenfald. I stedet bliver det tydeligt, at “han” korrellerer stærkest med sproget om udseende i den ene af de to klynger. Modsat ser vi en mere løs gruppering af sammenhænge, der tilsyneladende handler om læredrenge men også om tjenestepiger og har en klar protagonist (“min”, “mig”, mit”, der er fraværende institutionelle efterlysninger). Her finder vi også anknytningen til at tilkendegive opholdssted og advarslen om at huse og hæle. Ved hjælp af filtrering får vi altså et forslag om to forskellige, muligvis gensidigt ekskluderende, tematikker. Dem kunne vi bruge til at styre vores mere tætte læsninger eller til videre kvantitativ udforskning.
At disse tematikker antyder materialets kønnede dimensioner er måske den mest oplagte ledetråd. Vi kan prøve at isolere kønnede sted. Lad os også tilføje “mig” for at blive klogere på sammenfaldet imellem feminint kønnede stedord og ental. Lad os igen visualisere med geom_tile.
Token_df %>%
group_by(word) %>%
filter(n() > 140) %>%
pairwise_cor(word, ID) %>%
filter(item2 == "han" | item2 == "hun" | item2 == "mig") %>%
ggplot(aes(item1, item2, fill = correlation)) +
geom_tile() +
coord_fixed() +
scale_fill_gradient2(low = "red", high = "olivedrab", mid = "white", midpoint = 0) +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 7),
axis.text.y = element_text(size = 7),
legend.position = "top")
Imidlertid kan vi også bruge farve som en indikator på korrelation i vores netværksgraf. Det gør vi ved at udregne en simpel indikator på et ords kønnethed ved at trække ordets korrelation med “hun” fra ordet korrelation med “han”. Bemærk, at vi i denne proces lægger 1 til disse korrelationer først, så vi ikke løber ind i problemer ved at trække negative tal fra andre tal.
gender_cor <- Token_df %>%
pairwise_cor(word, ID) %>%
filter(item2 == "han" | item2 == "hun") %>%
mutate(correlation = correlation + 1) %>%
pivot_wider(names_from = item2, values_from = correlation) %>%
mutate(gender_indicator = han - hun)
Token_df %>%
group_by(word) %>%
filter(n() > 100) %>%
pairwise_cor(word, ID) %>%
filter(item1 > item2) %>%
slice_max(correlation, n = 500) %>%
as_tbl_graph(directed = FALSE) %>%
activate(nodes) %>%
left_join(Token_counts) %>%
left_join(gender_cor, by = c("name" = "item1")) %>%
ggraph(layout = "fr") +
geom_edge_link(aes(width = correlation), colour = "lightgrey") +
geom_node_point(aes(colour = gender_indicator), size = 5) +
geom_node_text(aes(label = name, size = n)) +
scale_size_continuous(range = c(1, 3)) +
scale_edge_width_continuous(range = c(0.1, 2)) +
scale_colour_gradient2(low = "red", high = "blue", mid = "grey90", midpoint = 0) +
theme_void() +
theme(legend.position = "none") +
ggtitle("Korrelationer imellem hyppige ord") +
labs(caption = "Farve indikerer høj korrelation med termen 'hun' (rød) eller 'han' (blå). Størrelse af label angiver hyppighed.",
subtitle = "Data: Efterlysningsannoncer fra Adresseavisen, 1780-1800")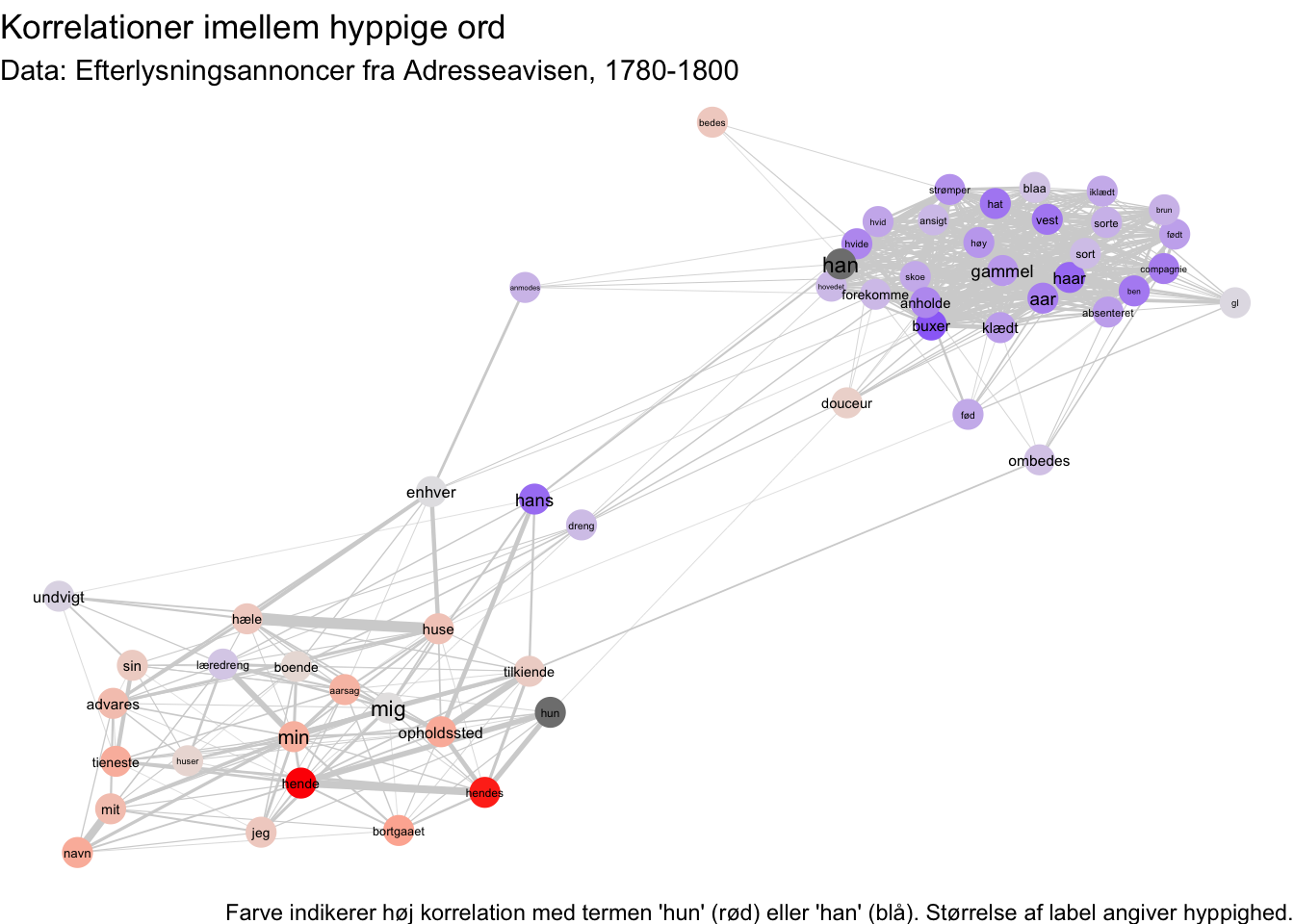
9.6 Addendum: Andre mål for sammenfald
I analyser af denne slags ser man ofte, at forskere (uden for historiefaget) bruger “Pointwise Mutal Information” (forkortet PMI) til at definere sammenfald. Dette er særlig score, med sin egen matematiske formel. Resultatet tilsvarer på flere måder phi-korrelationen. Hvis man af den ene eller anden grund hellere vil operere med PMI er det også muligt via en funktion i widyr-pakken:
Token_pmi <- Token_df %>%
group_by(word) %>%
filter(n() >= 5) %>%
pairwise_pmi(word, ID, sort = TRUE) %>%
mutate(pair = paste(item1, item2))
Token_cor <- Token_df %>%
group_by(word) %>%
filter(n() >= 5) %>%
pairwise_cor(word, ID, sort = TRUE) %>%
mutate(pair = paste(item1, item2))
Token_count <- Token_df %>%
pairwise_count(word, ID, sort = TRUE) %>%
mutate(pair = paste(item1, item2))
Token_pairwise_scores <- Token_pmi %>%
select(pmi, pair) %>%
left_join(Token_cor) %>%
select(pmi, correlation, pair) %>%
left_join(Token_count) %>%
filter(item1 > item2) %>%
select(item1, item2, n, pmi, correlation)Joining with `by = join_by(pair)`
Joining with `by = join_by(pair)`Token_pairwise_scores %>%
filter(n > 40) %>%
slice_max(pmi, n = 200) %>%
as_tbl_graph() %>%
activate(nodes) %>%
left_join(Token_counts, by = "name") %>%
ggraph(layout = "fr") +
geom_node_point(alpha = 0.3,
color = "#CC7800")+
geom_edge_link(aes(width = pmi),
alpha = 0.3,
show.legend = FALSE,
color = "#CC7800") +
geom_node_text(aes(label = name, size = n),
show.legend = FALSE,
color = "black",
repel = TRUE,
max.overlaps = 100) +
scale_edge_width_continuous(range = c(0.3, 2)) +
scale_size_continuous(range = c(1.5, 3)) +
theme_void() +
labs(caption = "Høje pmi-scorer\nStørrelse angiver hyppighed.\nAnnoncer fra København, 1780-1800.")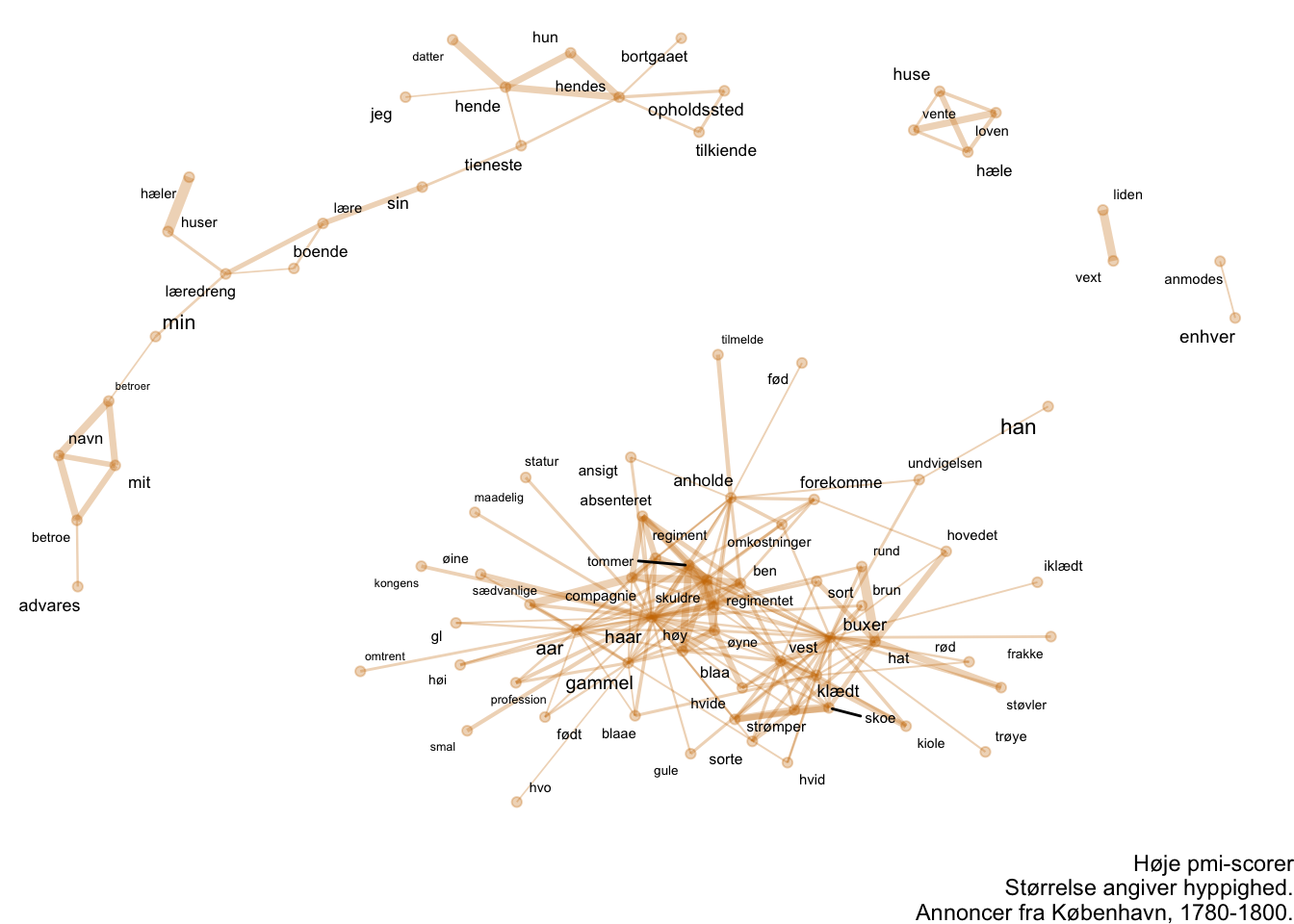
Token_pairwise_scores %>%
filter(n > 40) %>%
slice_max(correlation, n = 200) %>%
as_tbl_graph() %>%
activate(nodes) %>%
left_join(Token_counts, by = "name") %>%
ggraph(layout = "fr") +
geom_node_point(alpha = 0.3,
color = "#CC7800")+
geom_edge_link(aes(width = correlation),
alpha = 0.3,
show.legend = FALSE,
color = "#CC7800") +
geom_node_text(aes(label = name, size = n),
show.legend = FALSE,
color = "black",
repel = TRUE,
max.overlaps = 100) +
scale_edge_width_continuous(range = c(0.3, 2)) +
scale_size_continuous(range = c(1.5, 3)) +
theme_void() +
labs(caption = "Høje korrelation-scorer\nStørrelse angiver hyppighed.\nAnnoncer fra København, 1780-1800.")
Vi kan sammenligne netværkene for sammenfald målt på hhv. korrelation og PMI. Det er langt henad vejen de samme erkendelser de muliggør, men der er alligevel mindre forskelle.
Dette kapitel er løst bygget over fremgangsmåden udfoldet i Julia Silge og David Robinsons Text Mining with R.↩︎