4 Visualisering 1: Eksplorativ dataanalyse
I forrige kapitel introducerede jeg for en række klassiske greb i den kvantitative historikers værktøjskasse. I virkeligheden starter de fleste undersøgelser dog ikke med en række test. For de af os, der ikke er trænede statistiskere er der noget kontraintuitivt over at reducere data til nogle få udvalgte scorer. I stedet tænker vi typisk visuelt: når vi siger, at vi leder efter mønstre, implikerer det, at vi bruger øjnene.
I udgangspunktet er vi imidlertid vante til at tænke visualiseringen som en del af fomidlingen af data. Årsagen er åbenlys. Går vi langt tilbage - til en hedengangen tid, hvor det var dyrt og tidskrævende at visualisere data, giver det god mening, at visualiseringen først kommer til sidst, når vi synes, at vi har et result, vi kan vise frem. Imidlertid er det med et programmeringssprog som værktøj let at visualisere data, igen og igen. Det betyder, at vi kan tænke datavisualiseringen som et værktøj, der kan benyttes i alle undersøgelsens stadier. Ved at visualisere, igen og igen, data for vores egen erkendelses skyld, træner vi også vores egen evner til at afkode data visuelt. I en verden, hvor datavisualisering bliver vigtigere og vigtigere, er det sikkert ikke en uheldig færdighed.
I det seneste årti har netop det at visualisere som del af undersøgelsesprocessen vundet indpas i datavidenskab. Ofte citeres statistikeren John W. Tukey, der allerede i 1970erne argumenterede for, at datavisualisering var et fundamentalt redskab, der skulle generere og kvalificere de spørgsmål, vi stiller. Vi kan altså her tænke datavisualiseringen som en metode, hvorved vores opmærksomhed rettes - imod generelle træk eller imod det, som stritter imod. For Tukey var dette en eksperimentel proces: “To learn about data analysis, it is right that each of us try many things that do not work.”1 Det lyder famlende, men nogle gange kan det hjælpe vores erkendelse at tegne os frem, indtil et motiv viser sig. Tukey kaldte det også for grafisk detektivarbejde.
Datavisualisering er netop en af forcerne ved R. Dette skyldes især pakken ggplot2 (i daglig tale bare ggplot). Med få virkemidler kan vi med ggplot skabe både velkendte og eksperimentelle visualiseringer. Titlens “gg” (det ligner en typo) står for “grammar of graphics”, og pointen er ret bogstavelig: Pakken bygger på en ide om en almen grammatik for, hvordan ting plottes/tegnes. Uanset om vores diagram er af den ene eller anden type, bruger vi de samme byggesten. Vi har måske et vildt billede for vores indre øje, men kun ved at kende grammatikken, kan denne formuleres og gøres til et billede for andre.
Der findes allerede et væld af introduktioner til ggplot. Nogle er meget udførlige - og enkelte er endda skrevet af pakkens udviklere. Jeg vil derfor ikke gå ned i dybeste detaljer, men prøve at give en hjælpsom introduktion, der kan danne grobund for videre udforskning. Og jeg vil prøve at fokusere på ting, der netop er nyttige for historikere. Ikke, at vi som sådan er specielle, men vores datasæt har ofte et væld af kategoriserede data - og sjældent en masse ligefremme numeriske data. Modsat demonstrerer de introduktioner man finder på rundt omkring ofte deres pointer på data, der allerede består af tal.
Til formålet benytter vi samme data som i forrige kapitel: datasættet om ophold i Stokhusslaveriet i København fra 1741 til 1799. Og vi laver et par simple operationer på dataene allerede fra start. Dataene kan downloades her:
# Vi importerer på samme måde som i forrige kapitel
library(tidyverse)
library(readxl)
library(lubridate)
# Vi loader data og laver tekststrengen "NA" om til faktisk NA-værdier
df <- read_excel("data/Slave_1741_1800_clean.xlsx")
# Og vi skaber igen kolonnen om opholdets varighed
df <- df %>%
mutate(Ankomstdato = ymd(Indkommen),
Slutdato = ymd(Udkommen),
Varighed = as.numeric(Slutdato - Ankomstdato))4.1 Diagramtyper
Når vi skal igang med visualisere data, risikerer vi en form for lammelse, der bunder i de mange valg, vi øjeblikkeligt tvinges til at træffe - og måske også en bange anelse om, at der gælder en række regler, vi ikke kender. Hvilken diagramtype skal jeg vælge? Og hvordan bruger jeg dem rigtigt? I første omgang er svaret ikke helt ligetil. Der findes faktisk en helt masse mere eller mindre kodificerede regler for forskellige former for diagrammer (især i afsnit om visualisering i statistikbøger). Vi kan selvfølgelig trawle denne litteratur igennem og skrive alle reglerne op, men det ophæver næppe vores paralyserede tilstand. Så måske vil jeg nøjes med én enkelt grundregel: visualiser data for din egen skyld. I processen vil du lære, hvad der kommunikeres effektivt hvordan. Når du så har gjort dette, kan du måske læse nogle af alle de selvbestalte lovgiveres forskrifter - og vurdere om du vil praktisere akademisk ulydighed.
4.1.1 Søjlediagrammer
Det menneskelige øje er en drilsk størrelse. Når vi visualiserer data, kan vi knytte værdier til en lang række visuelle parametre: grafiske mærkers placering, længde, omfang, areal, form, farve, gennemsigtighed, mønstre og så videre. Vi kan tænke dette sådan, at vi knytter egenskaber ved vores data til egenskaber ved deres visuelle repræsentation. Mulighederne for kongruensfejl er mange, men heldigvis er skaden sjældent større, end at vores modtager får svært ved at afkode visualiseringen. Farve kan være særligt vanskelig, for en betragtelig del af befolkningen (især mænd), lider af en af de mange former for farveblindhed, der typisk gør, at vedkommende har svært ved at skelne udvalgte farver fra hinanden. Enkelte af os har problemer med stereoskopien - altså at få vores øjne til at arbejde sammen. Det betyder, at kontrastfyldte mønstre vil have en tendens til at svirre. Den slags må vi tage seriøst. Hvis vores visualisering ikke behøver kompleksitet, er der ingen grund til at introducere kompleksitet. Og hvis den faktisk gør, så må vi overveje nøje, hvordan vi får kompleksiteten i data til at afspejles på en intuitiv måde i visuel kompleksitet - uden at genere modtageren. Det er ofte et spørgsmål om at finde det bedste kompromis.
Nogle gange har klassikerne sin status af en grund. Søjlediagrammer er lette at læse, fordi vi kender deres konventioner, men også fordi øjet har relativt let ved at vurdere, om en ting er længere end en anden, hvis de optræder tæt på hinanden og er linet op på samme akse. Søjlediagrammer giver både læseren mulighed for en relativt præcis afkodning, men gør det også muligt at afkode informationerne hurtigt.
ggplot(df) +
geom_bar(aes(x = Baggrund))
Her får læseren en både letlæselig og intuitiv fornemmelse for mængderne. Kategorierne er placeret på x-aksen og ggplot forstår, at vi i udgangspunktet vil bruge geom_bar() til at tælle.
To ting er specifikke for ggplot og nyttige at forstå, før du går videre.
To ting er vigtige at have in mente, før du går videre:
Det første er brugen af +. Dette er ganske specifikt for ggplot, hvor hvert element føjes til med et + efterfulgt af koden. Det kan være svært at vænne øjet til. Logikken er noget i retning af, at vi med ggplot-kaldet først laver et kanvas, og at vi for hvert + lægger et lag mere på. Lidt som med lag i Photoshop.
Brugen af aes() er mere kompliceret. Denne funktion optræder altid inde i andre funktioner. I dette kapitel placerer jeg den i forbindelse med brugen af geomer - altså de konkrete figurer vi lægger på som lag. Man kan dog også specificere aes inde i selve ggplot-funktionen (i så fald “arver” hvert geom denne aes). Aes står for “aesthetic”. Det vi gør med funktionen er at vi knytter en æstetisk parameter (placering, farve, linjetype, form) til en værdi i vores data. Vil vi gerne specificere en æstetisk parameter, men uden at knytte denne til en variabel (hvis vi f.eks. bare vil have, at søjlerne skal være røde), specificerer vi denne parameter inde i samme geom-funktion, men uden for aes-funktionen. Eksemplificeret i næste visualisering.
Ofte vil vi lave en eller anden transformation af vores data før vi bruger ggplot. Disse kan vi med tidyverses syntaks gøre direkte forinden, for så at sende den bearbejdede data ind i visualiseringsfunktionen. Her får vi brug for velkendte verber.
df %>%
mutate(Afslutningsmåned = month(Slutdato,
label = TRUE,
abbr = FALSE)) %>%
select(Afslutningsmåned) %>%
na.omit() %>%
ggplot() +
geom_bar(aes(x = fct_rev(Afslutningsmåned))) +
coord_flip()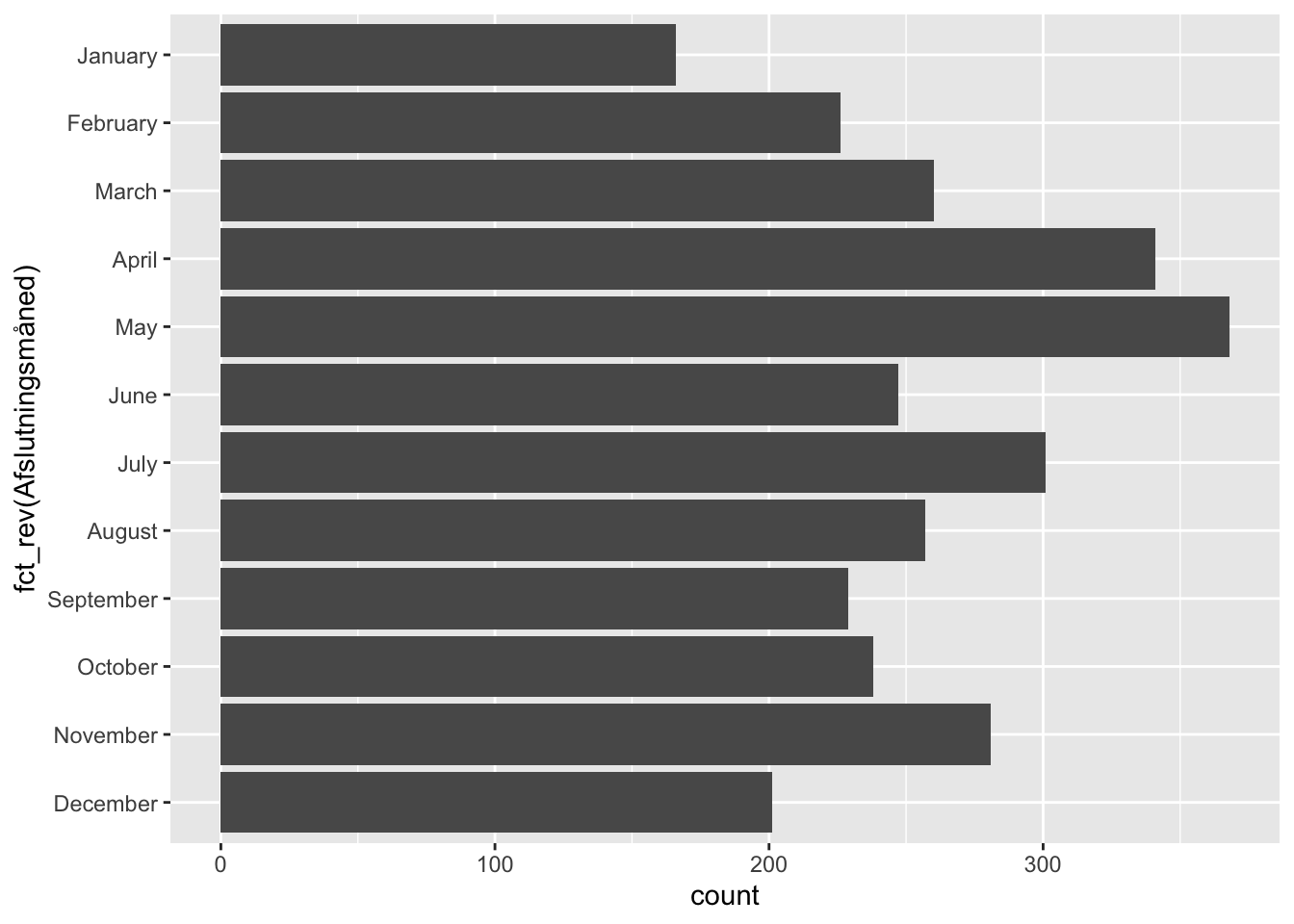
Kigger vi på variable med lange labels, kan det være en fordel at dreje vores plot 90 grader, så de ikke overlapper. Det har vi gjort ovenfor med coord_flip. Vi har også lavet om på månedernes rækkefølge med funktionen fct_rev. Uden denne kom månederne i omvendt rækkefølge efter at plottet var vendt.
Prøv at kigge på koden til de to diagrammer, vi har lavet indtil videre. Læg mærke til, hvor forskellene findes henne. Vi kan omforme vores data flere steder i et gglot-kald som dette.
Ofte bruger vi søjlediagrammerpå samme måder som vi bruger vores krydstabeller: Vi vil gerne kunne fornemme sammenhænge. Dette kan vi gøre ved at knytte andre variable til andre æstetiske parametre. F.eks. kan vi farve vores søjler med argumentet fill.
ggplot(df) +
geom_bar(aes(x = Baggrund, fill = Kropsstraf_kat))
Her bliver vi i stand til at afkode potentielle sammenhænge i dataene. Imidlertid kan det hurtigt blive forvirrende.
ggplot(df) +
geom_bar(aes(x = Baggrund, fill = Afslutning))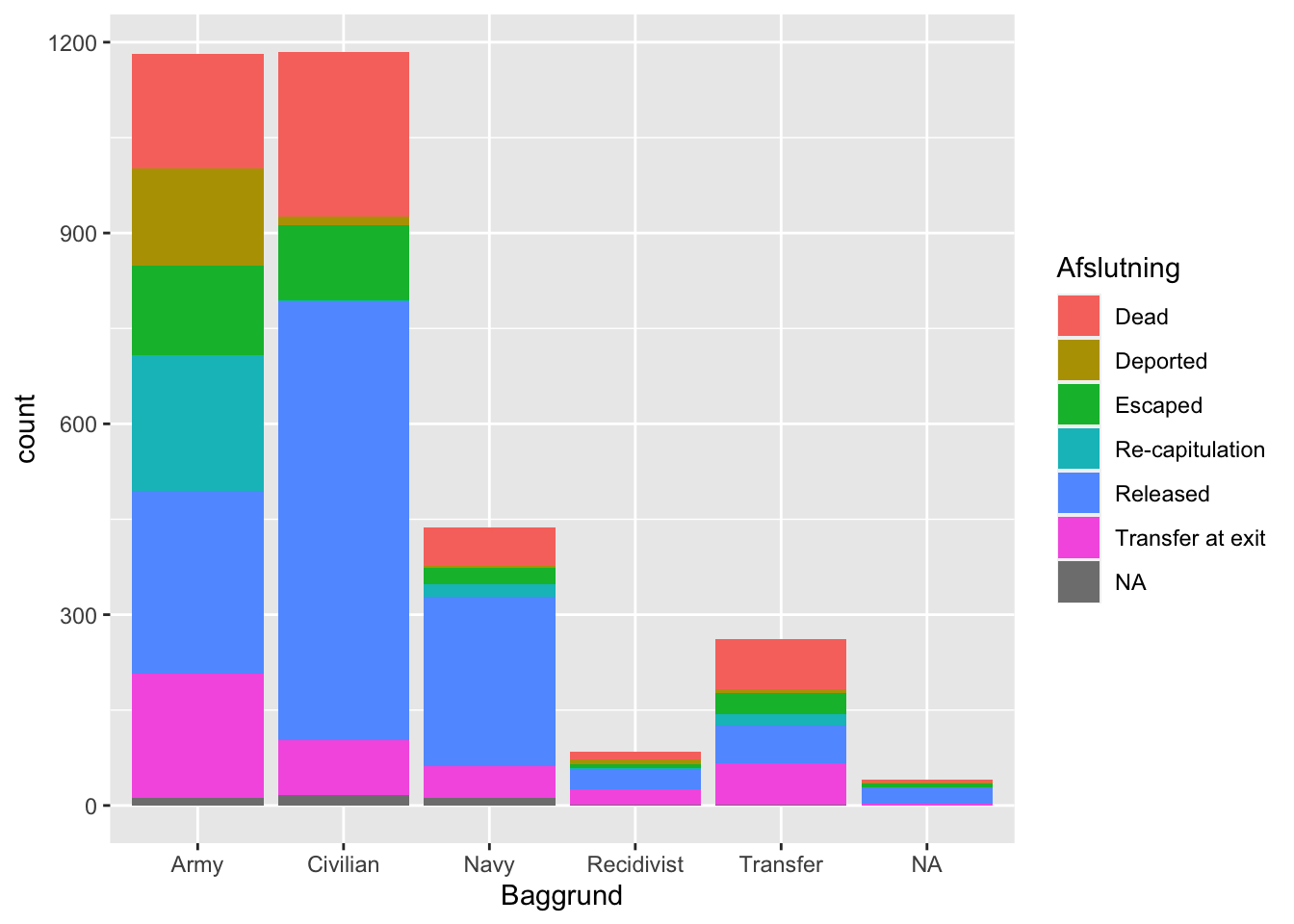
Ved at knytte syv forskellige kategorier til forskellige farver, gør vi os svært afhænge af vores legende. Nogle af farverne (selvom ggplot benytter rimeligt læsbare defaults) bliver også svære at skelne fra hinanden.
Sådan en visualisering kan måske tjene os selv, men ikke andre. Vi kan starte med at afbøde noget af skaden ved at fjerne NA-værdierne og vende om på de to variable. Når vi visualiserer mange variable på en gang er det imidlertid ofte tings proportionelle størrelse, der interesserer os. I sådanne tilfælde er vi måske bedre bedre tjent med at hver søjle blot ikke angiver totalen.
df %>%
select(Afslutning, Baggrund) %>%
na.omit() %>%
ggplot() +
geom_bar(aes(x = Afslutning, fill = Baggrund),
position = "fill")
Alternativt kunne også prøve at sideordne kategorierne.
df %>%
select(Afslutning, Baggrund) %>%
na.omit() %>%
ggplot() +
geom_bar(aes(x = Afslutning, fill = Baggrund),
position = "dodge")
Denne version kommunikerer relativt præcist, hvordan de enkelte kategorier angivet med farven fordeler sig. Men vi mister overblikket, fordi vi ikke har en klar indikator på totalen. Ofte vil vi netop stå i en situation, hvor vi skal beslutte om vi vil give en præcis afkodning af specifikke værdier eller et mere impressionistisk indtryk af overordnede træk. Spørgsmålet om, hvilken visualisering, der er bedst er således afhængigt af, hvad vi vil kommunikere.
Ovenfor ændrede vi radikalt på diagrammets udseende ved at give vores geom et position-argument. I udgangspunktet har de geom-funktioner vi bruger altid et default position-argument. Typisk er dette “identity”, der lidt firkantet sagt betyder, at tingen placeres der, hvor det giver mening i forhold til akserne. Geom-bar har dog en anden default, nemlig “stack”, der betyder, at værdier stables ovenpå hinanden. Ovenfor brugte vi to alternativer: position = fill og position = dodge. Prøv at leg med disse argumenter og få dig en fornemmelse for forskellen.
Geom_bar er vores go-to søjlediagram, fordi det er skabt til optællinger. Således behøver vi ikke fortælle ggplot, at der skal tælles. Arbejder vi med en tabel, hvor optællingerne allerede er foretaget, kan vi i stedet bruge geom_col. Her slipper vi dog aldrig for at specificere, hvilke data y-aksen skal knyttes til. Det kan vi derimod med geom_bar, fordi den i udgangspunktet tæller antallet af observationer, der matcher kategorierne på x-aksen.
Søjlediagrammet virker bedst til relativt simple optællinger og krydsninger. Det kommunikerer intuitivt om proportion. Det kommer til kort til kort, når der skal vises mange data. Og så alligevel. Nogle gange kan en lidt for kompleks visualisering måske tjene os til at genere generere spørgsmål til vores data? Ovenfor så vi ret store udsving ifht. hvilke måneder fangers ophold ophørte. Vi kan med få modifikationer tage samme kode og farve søjlerne ifht. typen af afslutning.
df %>%
mutate(Afslutningsmåned = month(Slutdato,
label = TRUE,
abbr = FALSE)) %>%
select(Afslutningsmåned, Afslutning) %>%
na.omit() %>%
ggplot() +
geom_bar(aes(x = fct_rev(Afslutningsmåned), fill = Afslutning)) +
coord_flip()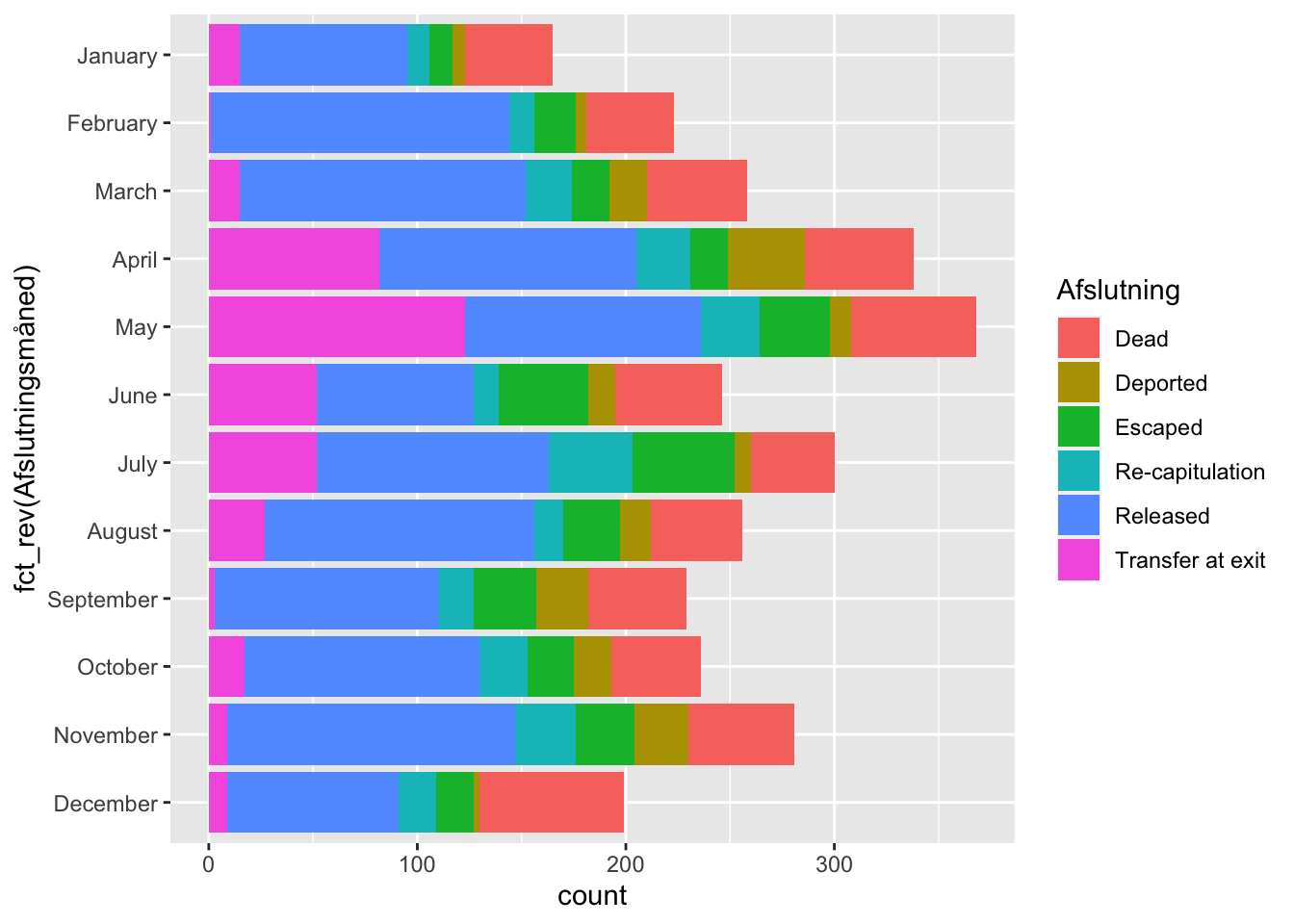
Hvilke spørgsmål kan vi rejse på baggrund af sådan en visualisering? Måske får vi nogle af svarene, hvis vi visualiserer videre?
4.1.2 Punktdiagrammer
Er der noget skønnere for forestillingsevnen end et simpelt punktdiagram? Nej. Det er som om tilstedeværelsen af mange små punkter får vores hjerne (min i hvert fald, måske er det bare mig), til at summe: “hvad ser jeg her?” Måske er det urmennesket i mig, der leder efter spor i mudderet.
Punktdiagrammet er et yndet diagram, når man kigger på to numeriske variabler på en gang. Et punktdiagram kan antyde sammenhænge imellem variablene.
ggplot(df) +
geom_point(aes(x = Alder,
y = Varighed))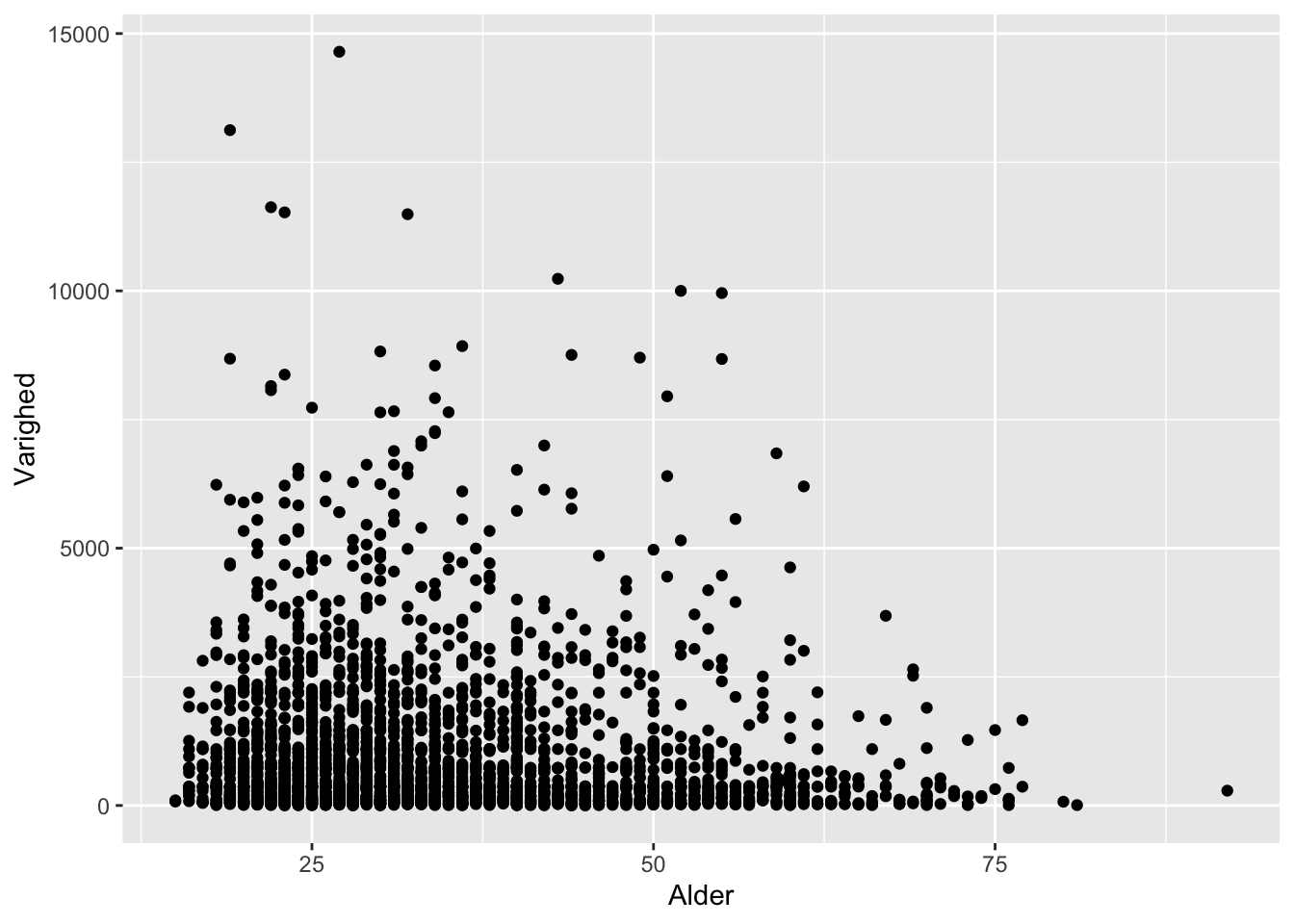
Vi kan tilføje en lille smule tilfældighed for at skille overlappende punkter ad:
ggplot(df) +
geom_jitter(aes(x = Alder,
y = Varighed))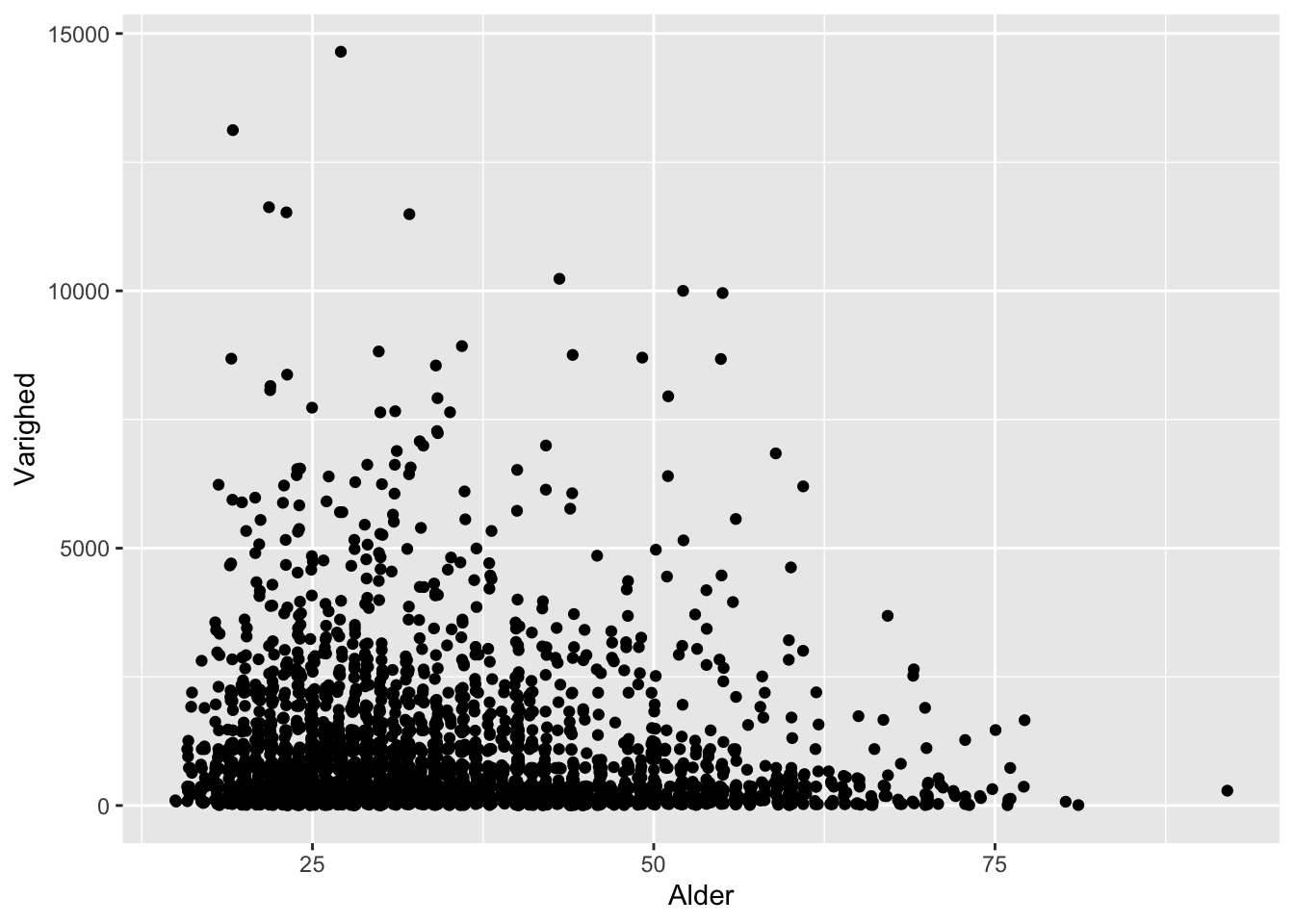
I nogle kontekster kan det være nyttigt at bruge en logaritmisk skala:
ggplot(df) +
geom_point(aes(x = Alder,
y = Varighed),
alpha = 0.15) +
scale_y_log10()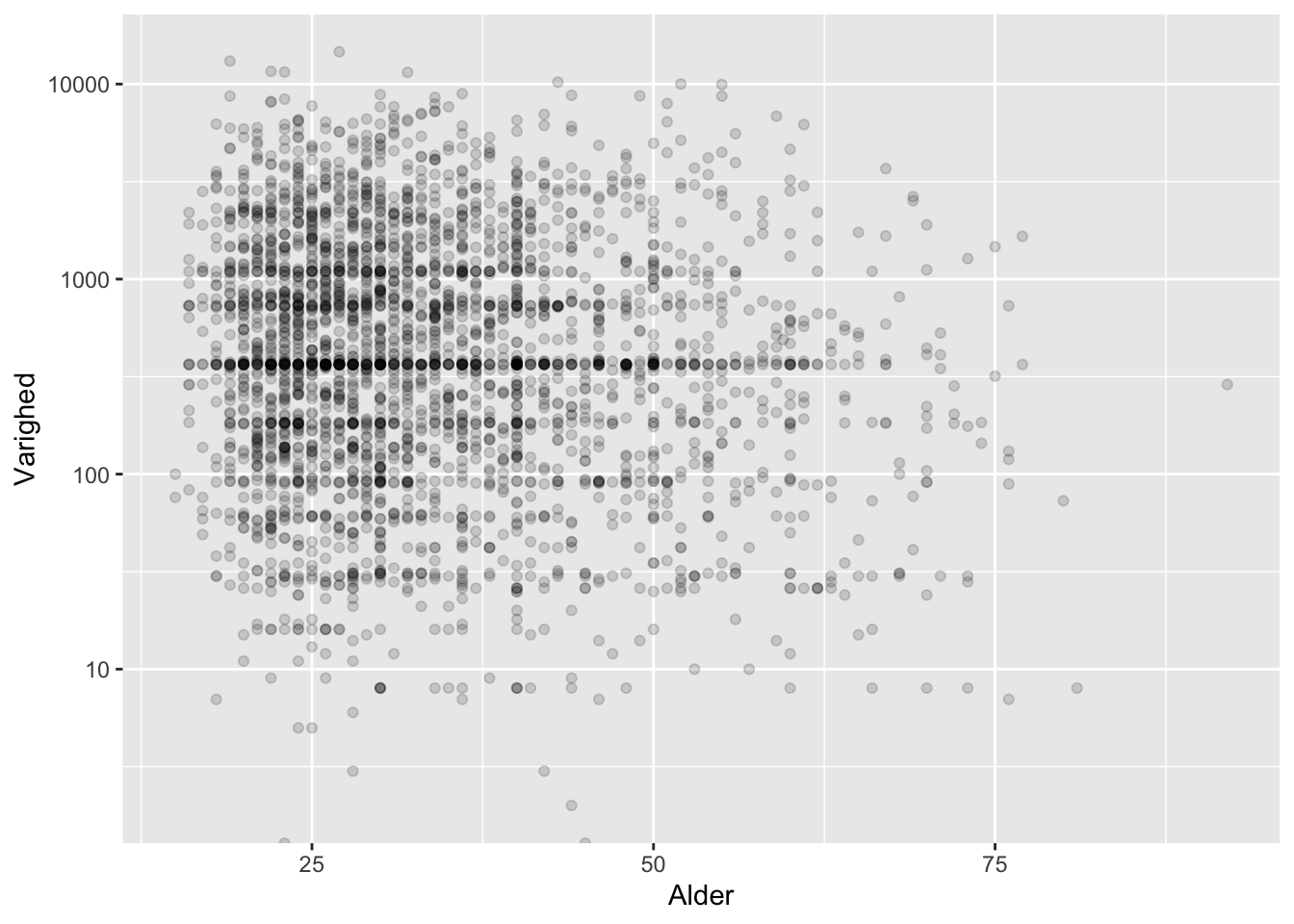
Ved at kigge nærmere ser vi flere bælter, der antyder, at data på begge akser klumper sammen om bestemte værdier (alder om runde cifre, varigheden om 6 måneder samt 1, 2 og 3 år).
En anden måde at at få en fornemmelse for tætheden af punkter er ved at antyde dette med konturlinjer (tænk det som et topografisk kort).
ggplot(df, aes(x = Alder,
y = Varighed)) +
geom_point(color = "grey") +
stat_density_2d(color = "Blue") +
scale_y_log10()
4.1.3 Lagkagediagrammer
Lagkagediagrammer hører hjemme i bestyrelseslokaler i lokale foreninger eller mellemstore virksomheder, hvor folk drikker danskvand af plastikflasker og foregiver at lave en ærlig dags arbejde.
Øjet har har svært ved at afkode areal. Så vi har svært ved at forstå, hvor stort hvert snit af kagen er (måske har sønderjyder en intuitiv fornemmelse, men jeg er af natur sådan indstillet, at et stykke kage altid bare er “for lille”). Ser man lagkagediagrammet som en søjle, hvor den ene spids æder den anden (det kaldes et “doughnut-diagram”), vil jeg anbefale, at man bare laver et søjlediagram i stedet.
4.1.4 Linjediagrammer - og andre måder at kigge på udvikling over tid
En anden klassiker er linjediagrammet og de mange beslægtede former, der ofte bruges til at vise en udvikling over tid. Vi kan starte med at prøve at identificere årstallet for hvert opholds start, for senere at kunne bruge det på en akse.
df <- df %>%
mutate(Ankomstår = year(Ankomstdato))Lad os prøve at se på, hvor mange indsættelser, der er pr. år:
df %>%
group_by(Ankomstår) %>%
summarize(n = n()) %>%
ggplot() +
geom_line(aes(x = Ankomstår, y = n))
Der er større udsving, end vi måske kunne have forventet. Lavpunktet omkring 1760 skyldes efter alt at dømme, at der i denne periode var en tilsvarende institution i direkte tilknytning til Kastellet - muligvis grundet en ombygning. I 1764 blev alle fanger fra Kastellets slaveri i hvert fald overført til Stokhusslaveriet, hvilket forårsager det store spike her. Det andet spike, i 1790, er resultatet af underlig proces, hvor myndighederne på Sjælland blev mobiliseret til at indfange tiggere og sende dem til Københavns fængsler.2 Mere end 70 fanger endte i Stokhusslaveriet ad denne vej. Generelt synes vi måske at kunne ane en generelt stigende tendens i kurven.
Ligesom med søjlediagrammet kan plotte flere forskellige grupper ved at knytte variable til andre æstetiske parametre. Linjer kan være af forskellige typer.
df %>%
group_by(Ankomstår, Kropsstraf_kat) %>%
summarize(n = n()) %>%
ggplot() +
geom_line(aes(x = Ankomstår,
y = n,
linetype = Kropsstraf_kat))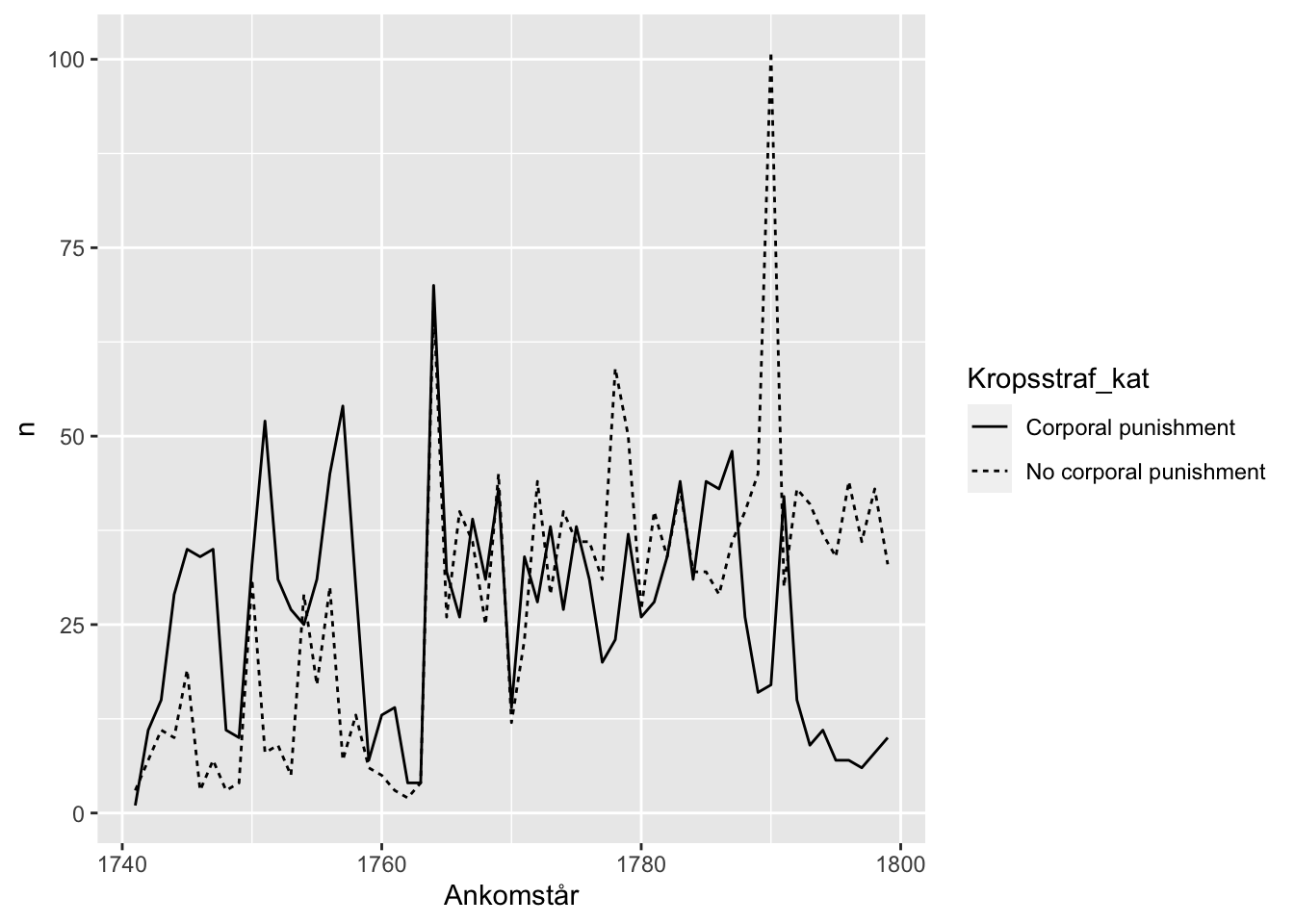
Her får vi en visualisering, der ved at begrænse sig til to linjer er nogenlunde læse og samtidig antyder en udvikling i brugen af kropsstraffe i forbindelse med fængselsophold. Det ser ud som, at det går af mode omkring 1790.
Flere forskellige linjetyper er effektivt, men stiger antallet af kategorier, får vi hurtigt svært ved at skelne dem. Fra hinanden. Farver kan naturligvis stadig bruges.
df %>%
mutate(Ankomstår = as.factor(Ankomstår),
Baggrund = as.factor(Baggrund)) %>%
group_by(Ankomstår, Baggrund, .drop = FALSE) %>%
summarise(n = n()) %>%
na.omit() %>%
ggplot() +
geom_line(aes(x = as.numeric(as.character(Ankomstår)),
y = n,
color = Baggrund)) +
xlab("Ankomstår")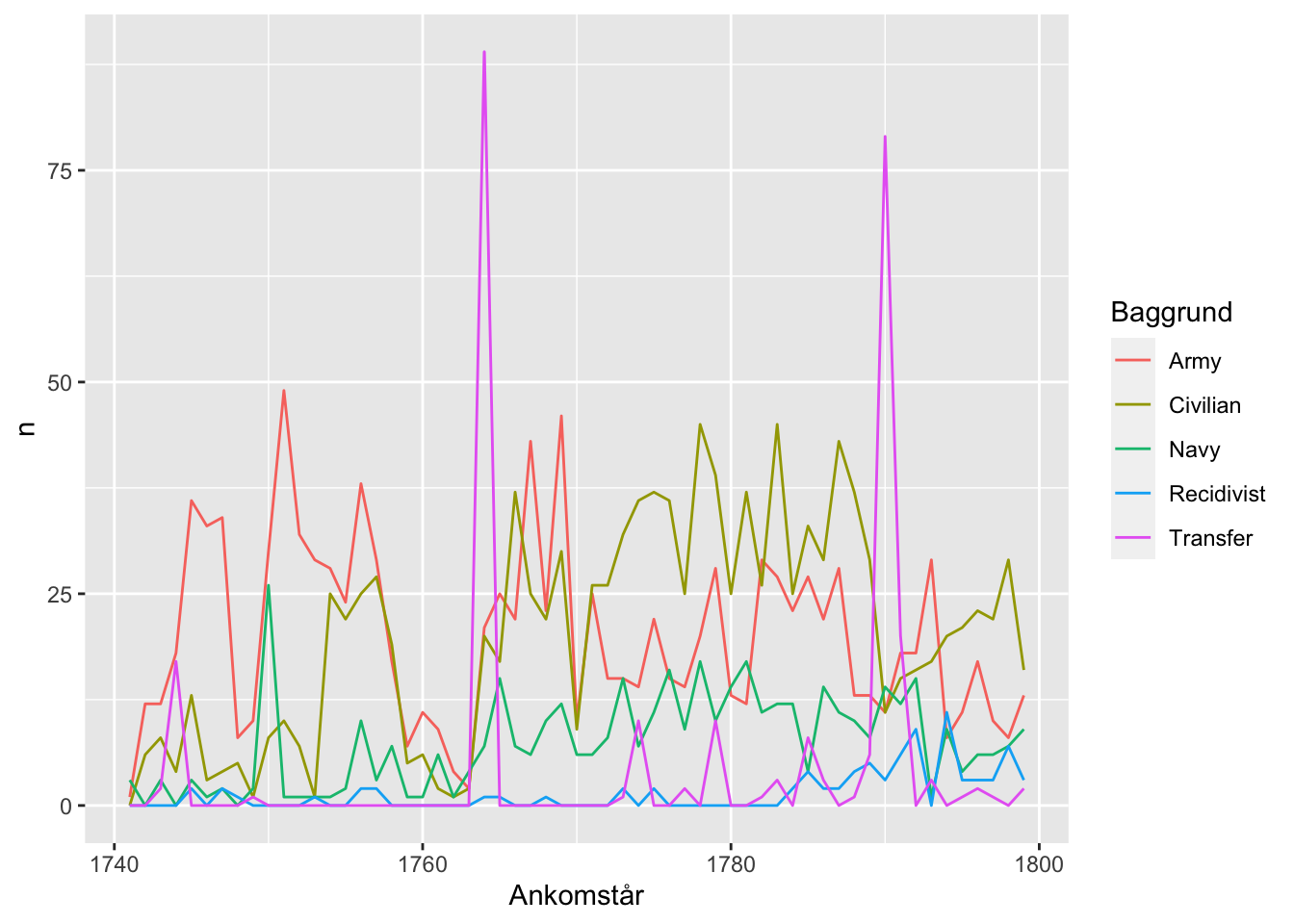
Koden er her lidt mere omstændig. Vi er nødt til at springe gennem nogle huller, for hvis ikke filtrerer vores group_by rækker uden værdier helt væk - og derfor optæller de ikke. Resultatet ville ellers blive, at geom_line forbandt på tværs af år med 0 nyankomne i en given kategori. Alternativt ville grafen have set sådan her ud:
df %>%
group_by(Ankomstår, Baggrund) %>%
summarise(n = n()) %>%
ggplot() +
geom_line(aes(x = Ankomstår,
y = n,
color = Baggrund))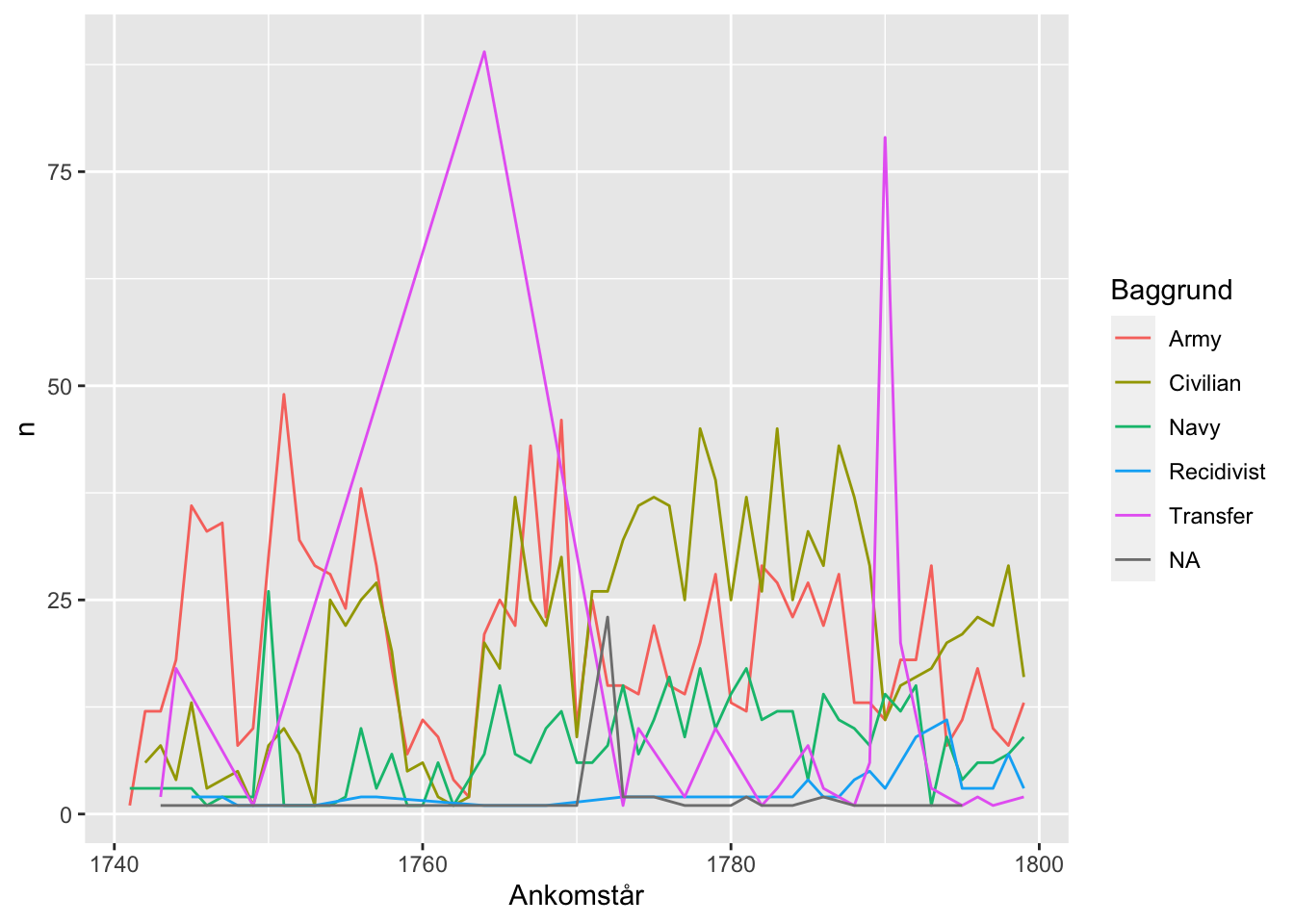
Læg mærke til, hvordan linjerne her forbinder på tværs af år, men 0 ankomne i kategorien “Overført”. Dette er åbenlyst misvisende. Derfor den mere omstændige kode.
I virkeligheden kunne vi have lavet samme visualisering, med et andet geom. Dette hedder geom_freqpoly. Fordi det netop retter sig imod at optælle en frekvens løser det problemet med en langt simplere kode. Når vi ikke bare bruger dette i første omgang er det dog, fordi problemet med de manglende værdier også kan dukke op ifht. andre geomer uden en let erstatning. Det kan derfor være nyttigt at kende en vej rundt om problemet.
df %>%
select(Ankomstår, Baggrund) %>%
na.omit() %>%
ggplot() +
geom_freqpoly(aes(x = Ankomstår,
color = Baggrund),
binwidth = 1)
Har vi brug for at vise flere tings udvikling, kan man i stedet bruge geom_area. I stedet for en linje får vi her et udfyldt areal. Dermed taber vi præcision, men bliver i stand til lettere at forholde kategorier ifht. hinanden.
Vi kan i samme ombæring prøve nogle andre farver. Det svirrer lidt. For at ændre på farverne kan vi starte med at knytte dem til en foruddefineret farvepalette.
library(RColorBrewer)
df %>%
mutate(Ankomstår = as.factor(Ankomstår),
Baggrund = as.factor(Baggrund)) %>%
group_by(Ankomstår, Baggrund, .drop = FALSE) %>%
summarise(n = n()) %>%
na.omit() %>%
ggplot() +
geom_area(aes(x = as.numeric(as.character(Ankomstår)),
y = n,
fill = Baggrund),
linewidth = 0.1, color = "black") +
xlab("Ankomstår") +
scale_fill_brewer(palette = 13) +
theme_minimal()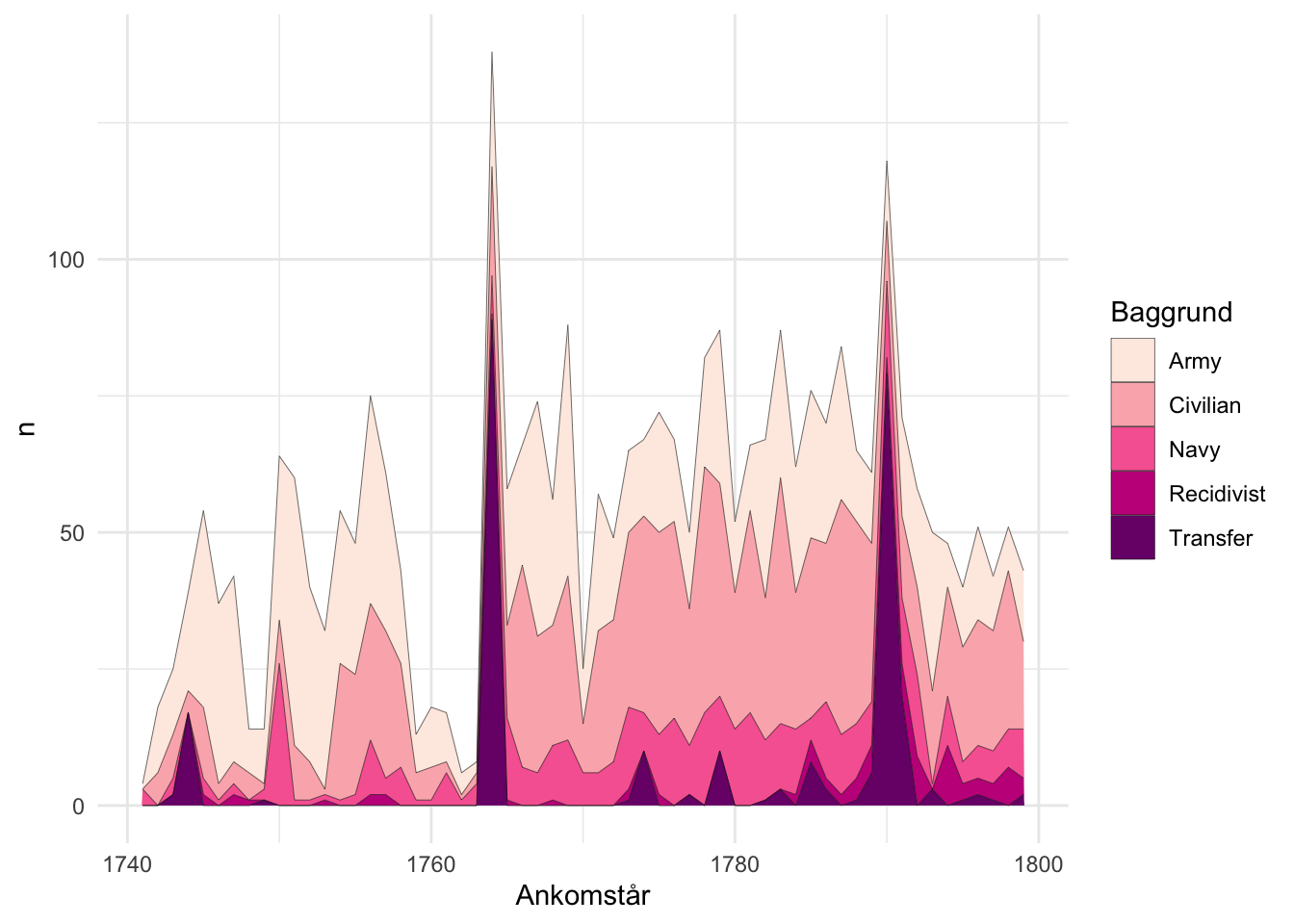
Visualiseringen har den styrke, at den gør det muligt at se udvikling og udsving i totalen - og giver et indtryk at fordelingen på tværs af kategorierne. Det sidste er dog en lille smule svært at afkode præcist.
Læg mærke til brugen af theme_minimal(). Ggplot indeholder en række templates for hvordan vores visualiseringers baggrund, akser, linjer etc. skal se ud. Prøv dig frem og find et du kan lide og som passer til visualiseringen. Senere i dette kapitel skal vi se på, hvordan man selv skaber sit diagrams “theme”.
I alle de ovenstående visualiseringer har vi søgt at kommunikere præcise værdier. Dermed får vi blik for udsving og kan generere hypoteser om, hvad der driver et pludseligt spike eller fald. Nogle gange vil vi imidlertid hellere vise en trendlinje. Denne viser et udjævnet gennemsnit af værdierne og kan derfor give os en fornemmelse for, hvordan en udvikling ser ud i mere overordnede træk.
ggplot(df) +
geom_smooth(aes(x = Ankomstår,
y = Varighed))
Skyggerne fortæller os om 95%-konfidensintervallet. Dette betyder firkantet sagt, at hvis vi fik 100 tilsvarende samples af data ville vi statisk kunne forvente, at 95% af disse lå inden for dette bånd. Med andre ord fortæller det os noget om sikkerheden af den tendens vi ser.
4.1.5 Histogrammer og andre måder at se fordelinger
Et simpelt, men meget effektivt instrument til at vise hvordan værdier fordeler sig er histogrammet. Tænk på det som den visuelle ledsager til de simple beskrivende mål, vi brugte i forrige kapitel.
ggplot(df) +
geom_histogram(aes(x = Alder))`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.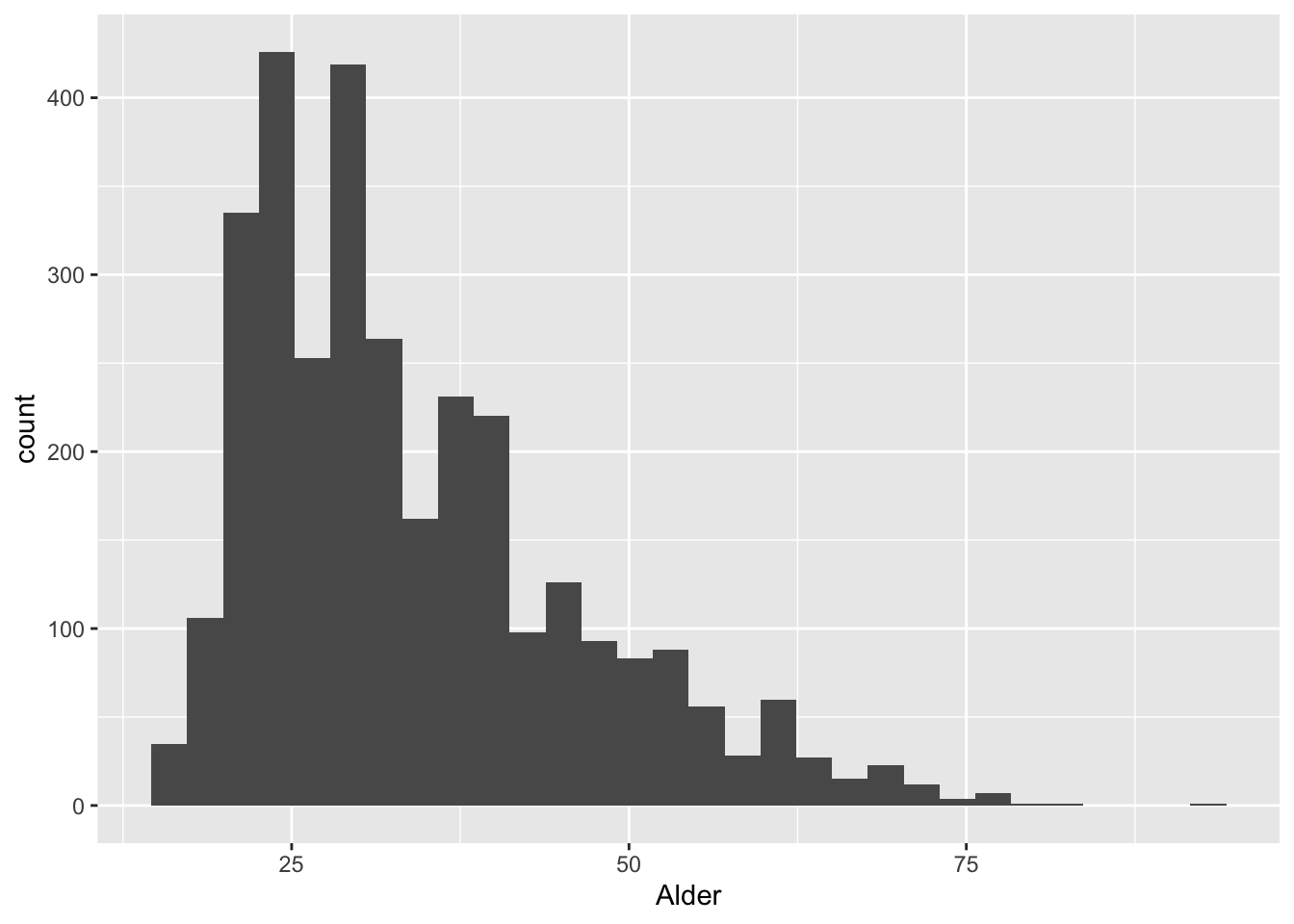
Her får vi en fornemmelse for, at fordelingen af fangernes alder er skæv. Histogrammet grupperer værdierne i klumper, med henblik på at give et indtryk af dataenes generelle konturer. Ved at ændre på binwidth-argumentet kan vi imidlertid justere på denne inddeling. Vælger vi værdien 1 vil søjlerne matche en eksakt værdi.
ggplot(df) +
geom_histogram(aes(x = Alder),
binwidth = 1)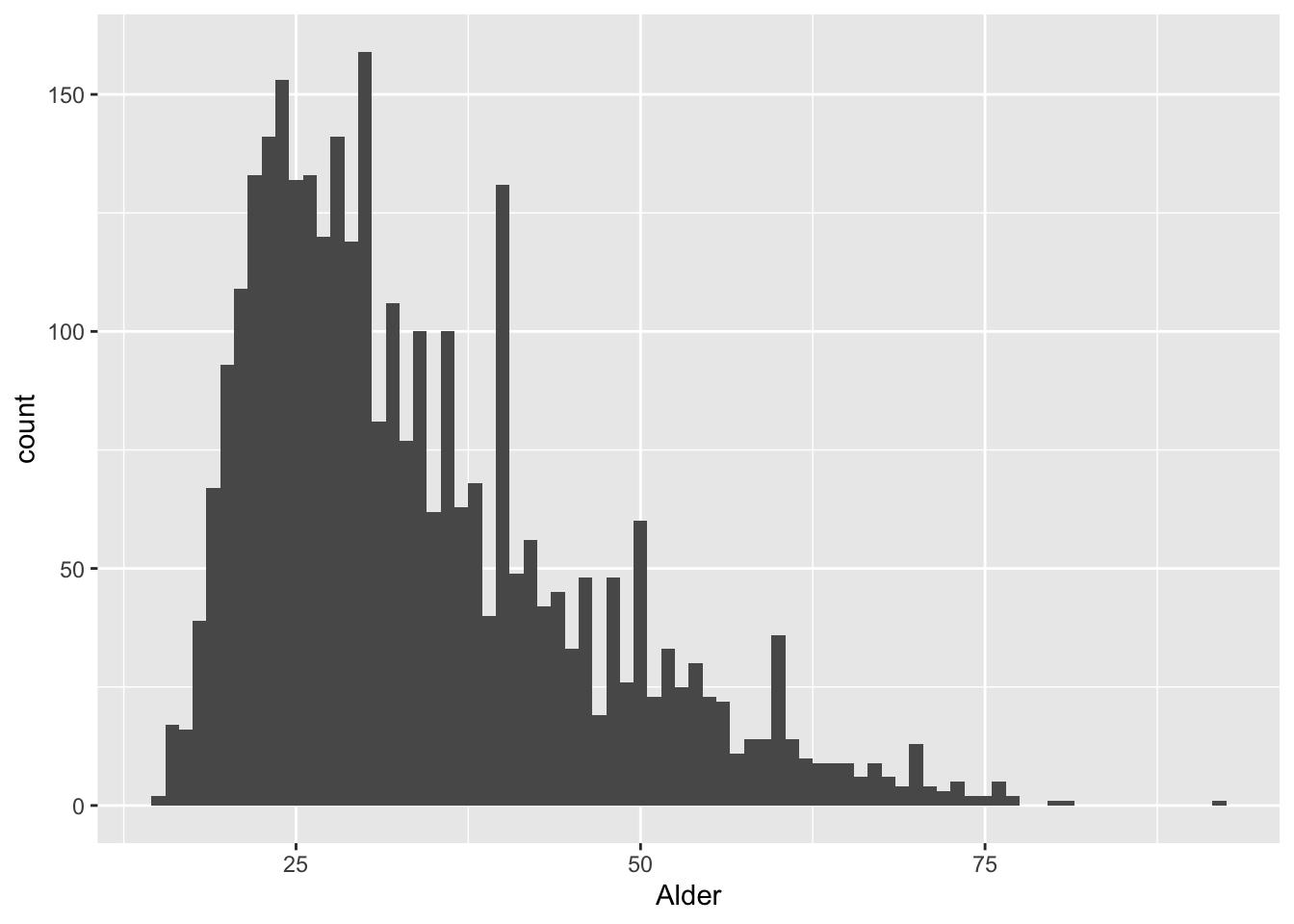
Bemærk mønsteret! En simpel visualisering kan her generere at spørgsmål: hvorfor klumper fangernes aldre sig sammen om bestemte værdier. Et svar kræver en grundig overvejelse over hvordan aldersangivelserne er blevet til. De har givetvis hvilet på fangens egne ord, da skriveren i fængslet ikke har haft mulighed for at konsultere fangens sogns kirkebog. Det er altså højst sandsynligt fangen selv, der runder af. Dette kan vi tolke som et udtryk for talfærdigheder eller mangel på samme.
Er vi interesserede i hvordan værdier fordeler sig for forskellige grupper, kan vi selvfølgelig producerer small multiples af sådanne histogrammer. En anden mulighed er at ty til et såkaldt boxplot - eller et box-and-whiskers-plot som dets opfinder (førnævnte John Tukey) kaldte det.
ggplot(df) +
geom_boxplot(aes(x = Baggrund,
y = Alder))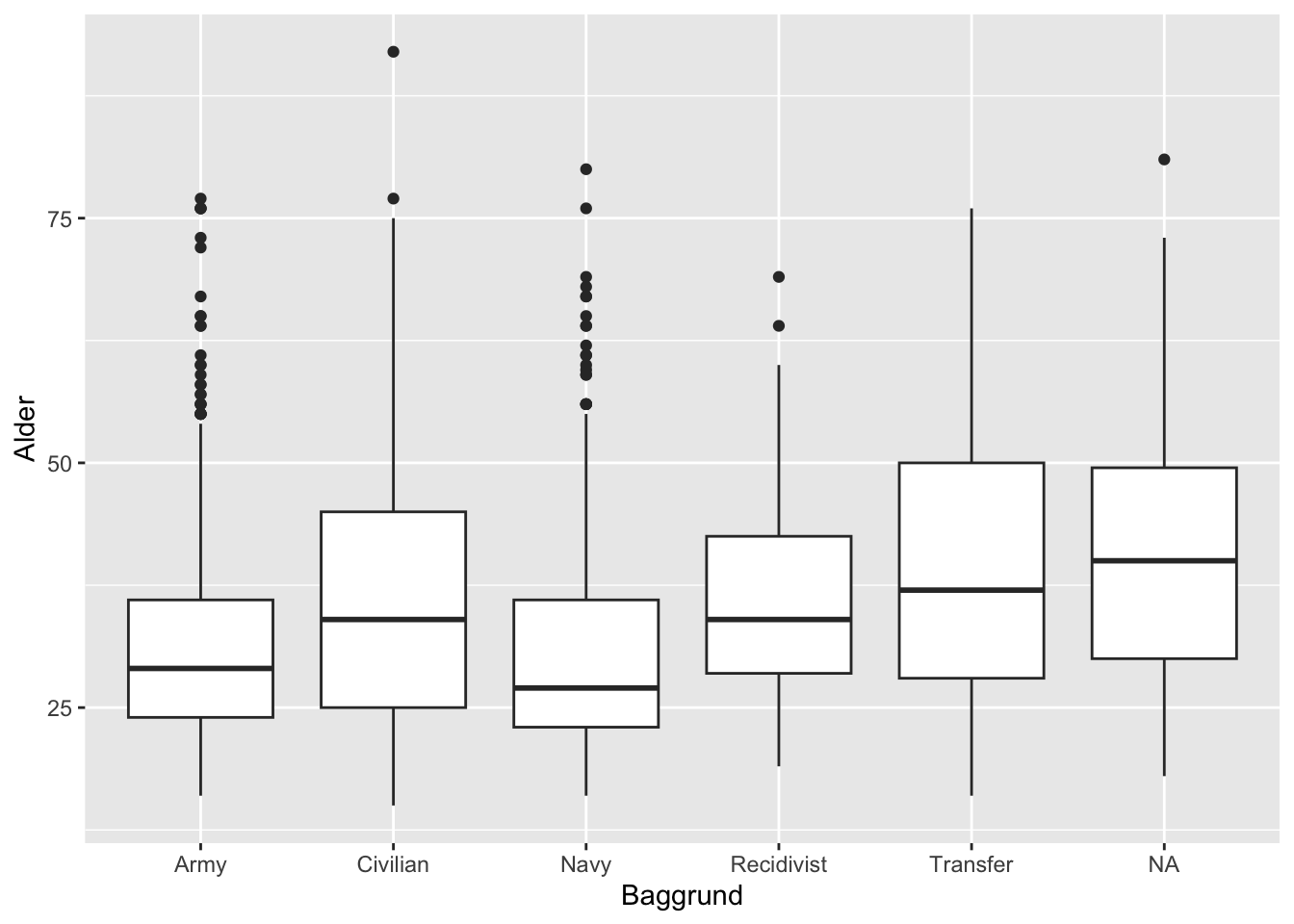
Denne visualisering give ros mange af de samme oplysninger som vi fik med quantile-funktionen i forrige kapitel. Men den giver viser disse for hver gruppe. Stregen i midten af hver firkant er medianen for gruppen. Boksen strækker sig så til øvre og nedre kvartil. Stregen (Tukeys knurhår?) definerer et spænd der svarer til spændet imellem de to kvartiler * 1.5 - men kun i tilfælde af, at der findes værdier, der falder indenfor dette, ellers kortes stregen af ved den yderste observation. De små prikker for nogle af kategorierne defineres som outliers.
Boxplottet er en personlig favorit for mig. Det giver en masse oplysninger, men kan også læses relativt intuitivt. Det opfylder dermed drømmen om at give et hurtigt, men mættet blik på mønstre. Med lidt justering og funktionen cut_interval kan vi endda også bruge det til at visualisere ting over tid.
ggplot(df) +
geom_boxplot(aes(x = fct_rev(cut_interval(Ankomstår, n = 10)),
y = Varighed)) +
coord_flip(ylim = c(0, 1800))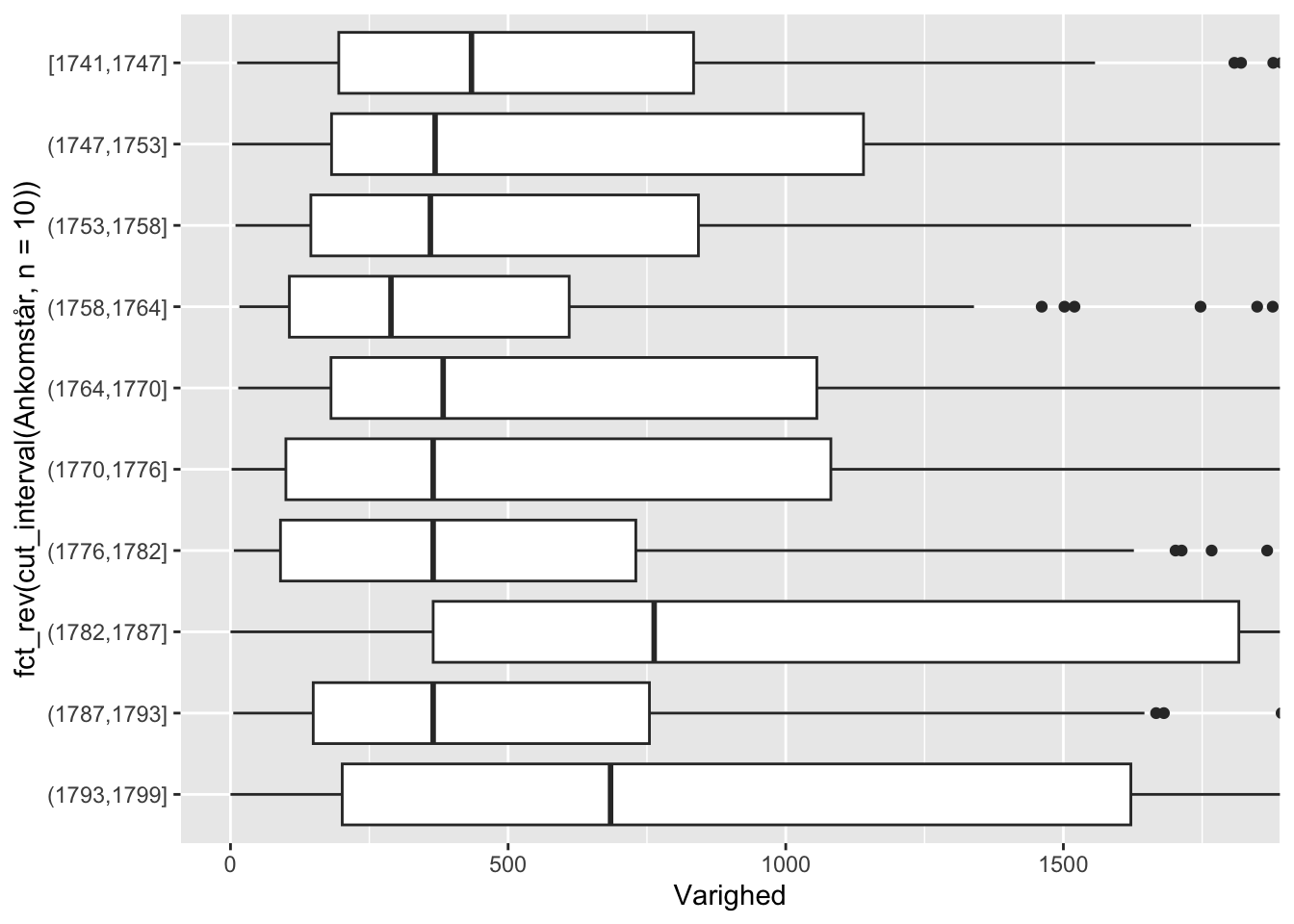
Her får vi en fornemmelse for, at varigheden af opholdene svinger ret dramatisk. Med udsving i perioden omkring 1760 og med ret voldsomme stigninger imod slutningen af perioden (disse fortsatte ind i 1800-tallet, hvor fængselsophol generelt blev markant længere. Bemærk hvordan vi ved hjælp af coord_flip både har roteret plottet og har skåret det til. Det kan i mange tilfælde være nyttigt at vende et boxplot på siden. Men her kradser det måske vores hjerne lidt, for vi forventer intuitivt, at tid optræder på vandrette akser.
Et alternativ til det klassiske boxplot, er det såkaldte violinplot:
ggplot(df) +
geom_violin(aes(x = Baggrund,
y = Alder),
draw_quantiles = c(0.25, 0.5, 0.75),
adjust = 0.5)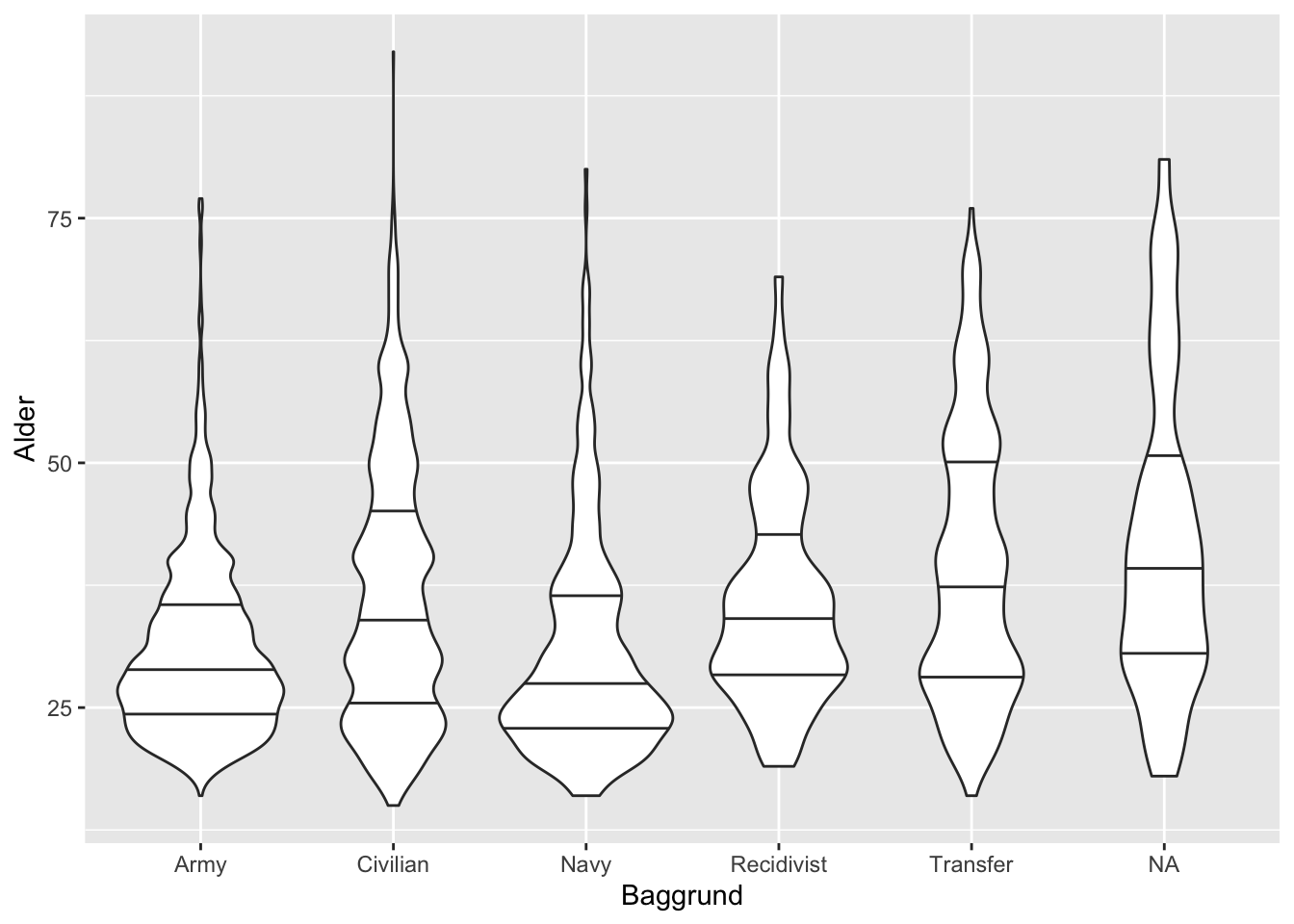
4.2 Simple lineære modeller
Vil vi kommunikere en generel trend, kan vi i stedet prøve en anden teknik: at vise data som et simpelt og abstrakt mønster. Den mest klassiske strategi er nok, at fitte en lineær model på dataene. En sådan model forsøger at tegne den lige linje, der passer bedst på vores data.
df %>%
select(Ankomstår, Alder, Livstid) %>%
na.omit() %>%
ggplot() +
geom_smooth(aes(x = Ankomstår,
y = Alder,
colour = Livstid),
method = "lm") +
theme_bw()`geom_smooth()` using formula = 'y ~ x'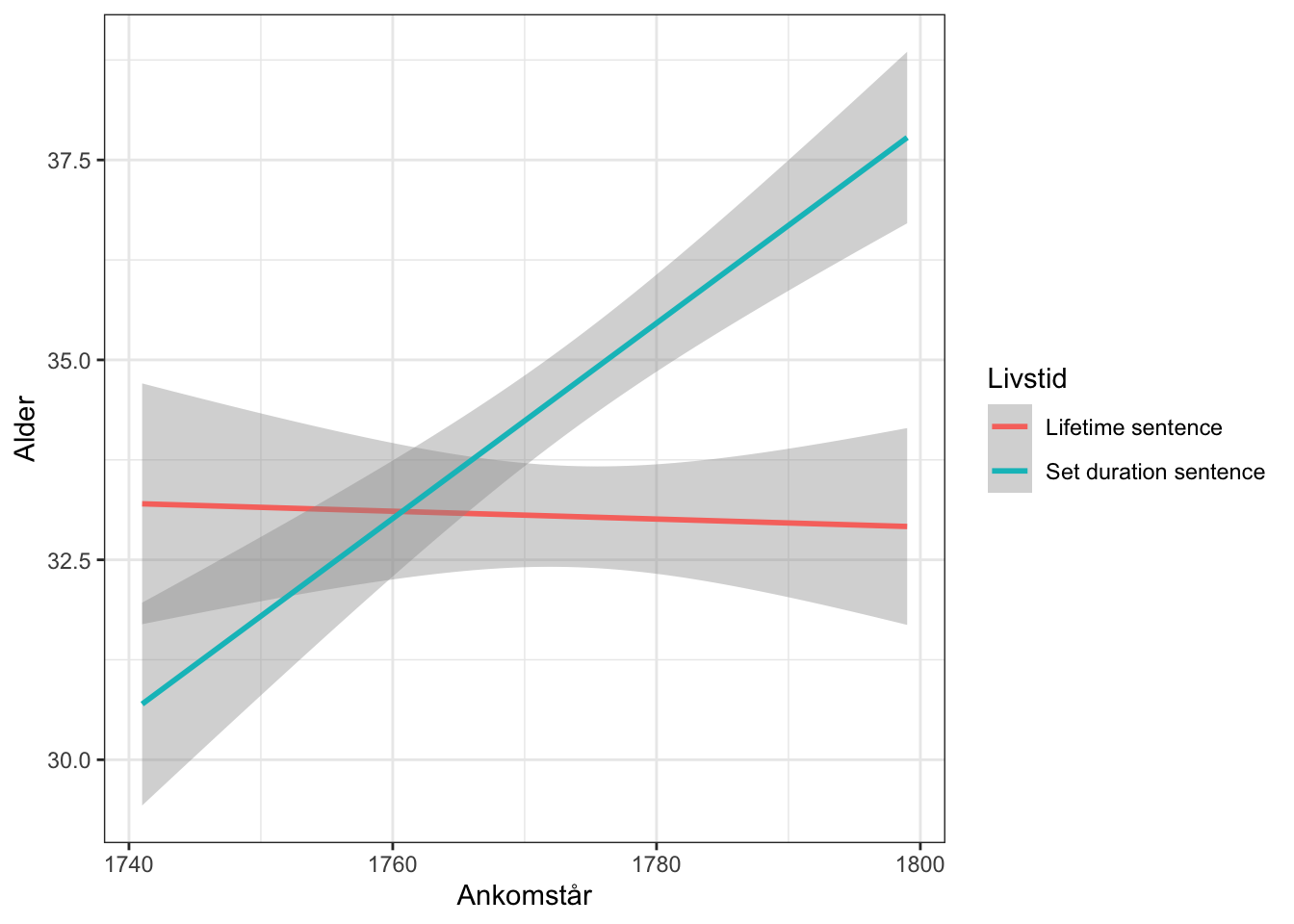
De fanger, der ankommer med en åremålsstraf bliver med tiden markant ældre, imens alderen for dem med livstidsstraffe ikke ændrer sig. Skyggerne på visualiseringen kommunikerer 95%-konfidensintervallet. Selvom vi har en betragtelig statistisk usikkerhed ser vi alligevelen udvikling. Hvad kan mon forklare den?
4.3 Mange små visualiseringer - small multiples
Ovenfor er vi flere gange stødt på samme problem: Vi vil gerne visualisere mere data, end visualiseringen kan bære. En løsning kan være, at producere et separat, mindre diagram for hver kategori. Dette gøres ved hjælp af funktinen facet_wrap. Det har heldigvis ikke nogen forbindelse til offentlige kantiners tendens til at vikle en salat ind i en kolde tortilla. Det har derimod alt at gøre med grafikeren og dataekvilibristen Edward Tufte, der i et tidligt pragtværk om datavisualiseringen argumenterede for ideen om at lave “small multiples” - altså gentagne, men små versioner af samme simple diagram, så disse kunne sammenlignes eller læses serielt.
df %>%
mutate(Ankomstår = as.factor(Ankomstår),
Baggrund = as.factor(Baggrund)) %>%
group_by(Ankomstår, Baggrund, .drop = FALSE) %>%
summarise(n = n()) %>%
na.omit() %>%
ggplot() +
geom_area(aes(x = as.numeric(as.character(Ankomstår)),
y = n)) +
facet_wrap(~ Baggrund) +
xlab("Ankomstår")
Med enkelte mindre justeringer (og bare rolig, vi skal nok vende tilbage til, hvordan alt justeres!), kunne dette sagtens virke. Kigger vi på de små diagrammer ser vi ganske forskellige mønstre. Som vi så med forsøgene på at vise samme mønstre med geom_line, geom_freqpoly og geom_area var disse mønstre svære at gøre læselige i bare et enkelt diagram, fordi vi endte med svirrende farver og krydsende linjer. Tufte havde fat i den lange ende.
Måske er jeg primært interesseret de tre største grupper, men vil gerne have en udstrakt x-akse, fordi det trods alt er en lang tidsperiode. Dette kan jeg opnå ved første at filtrere datasættet og til sidst bruge facet_grid i stedet for facet_wrap.
df %>%
filter(Baggrund == "Army" | Baggrund == "Civilian" | Baggrund == "Navy") %>%
mutate(Ankomstår = as.factor(Ankomstår),
Baggrund = as.factor(Baggrund)) %>%
group_by(Ankomstår, Baggrund, .drop = FALSE) %>%
summarise(n = n()) %>%
na.omit() %>%
ggplot() +
geom_area(aes(x = as.numeric(as.character(Ankomstår)),
y = n)) +
facet_grid(rows = vars(Baggrund)) +
xlab("Ankomstår") +
theme(aspect.ratio = 0.4/1)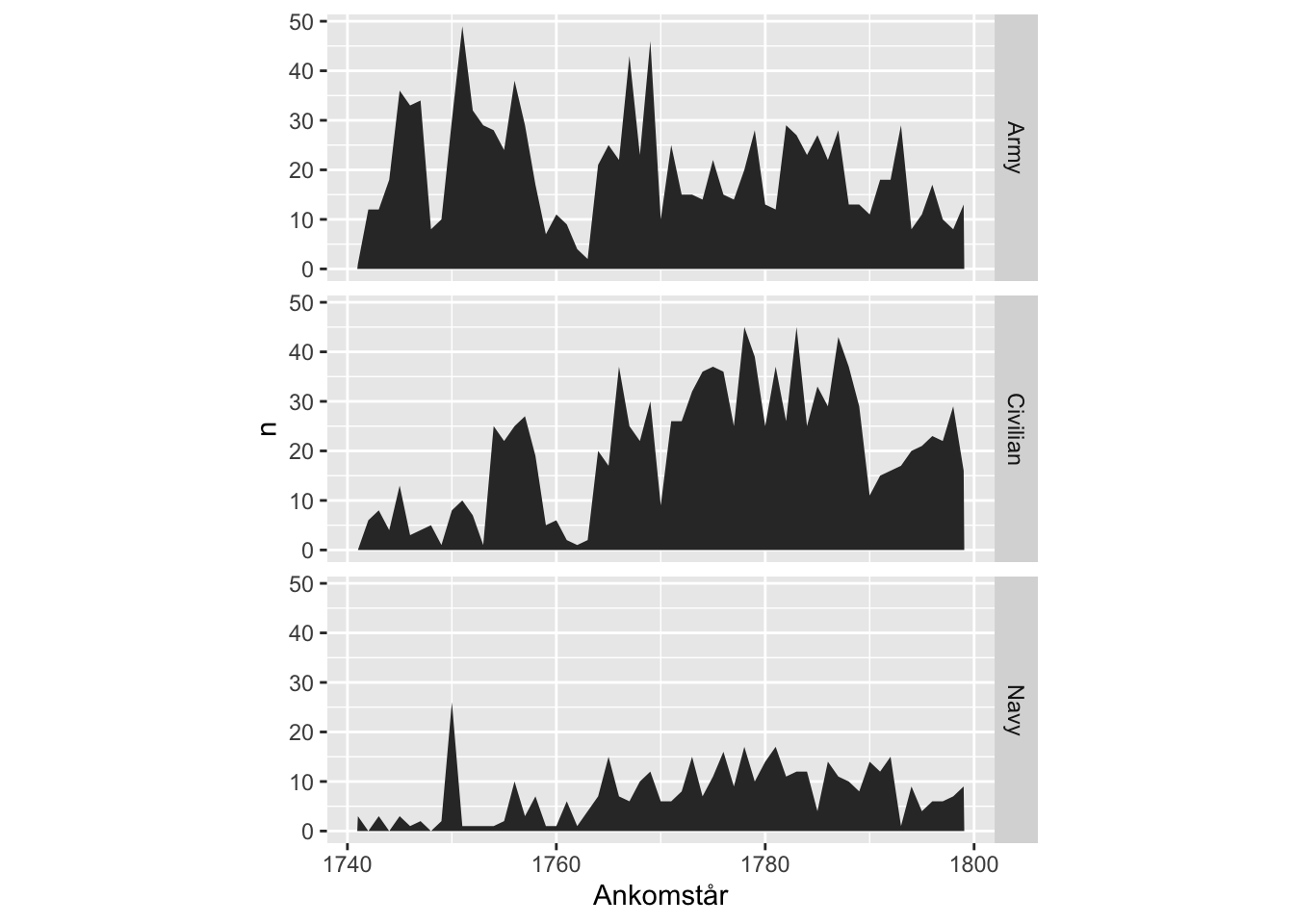
Det er ikke en smuk visualisering i æstetisk forstand, men den kommunikerer præcist: Der sker et skift, hvor der i løbet af perioden bliver relativt færre eks-soldater og flere civile.
Small multiples kan kommunikere simpelt til vores læser. De kan også give os små datamættede visualiseringer vi kan bruge til at få vores forestillingsevne i sving, så vi kan generere nye spørgsmål til dataene.
Lad os forsøge ved at lave en serie af punktdiagrammer:
df %>%
select(Ankomstår, Alder, Kropsstraf_kat, Afslutning) %>%
na.omit() %>%
ggplot() +
geom_jitter(aes(x = Ankomstår,
y = Alder,
color = Kropsstraf_kat,
shape = Kropsstraf_kat)) +
facet_wrap(~ Afslutning) +
theme(legend.position = "bottom",
axis.text.x = element_text(size = 5)) +
ggtitle("Fangers alder ved ankomst, inddelt efter fængselsopholdets afslutning")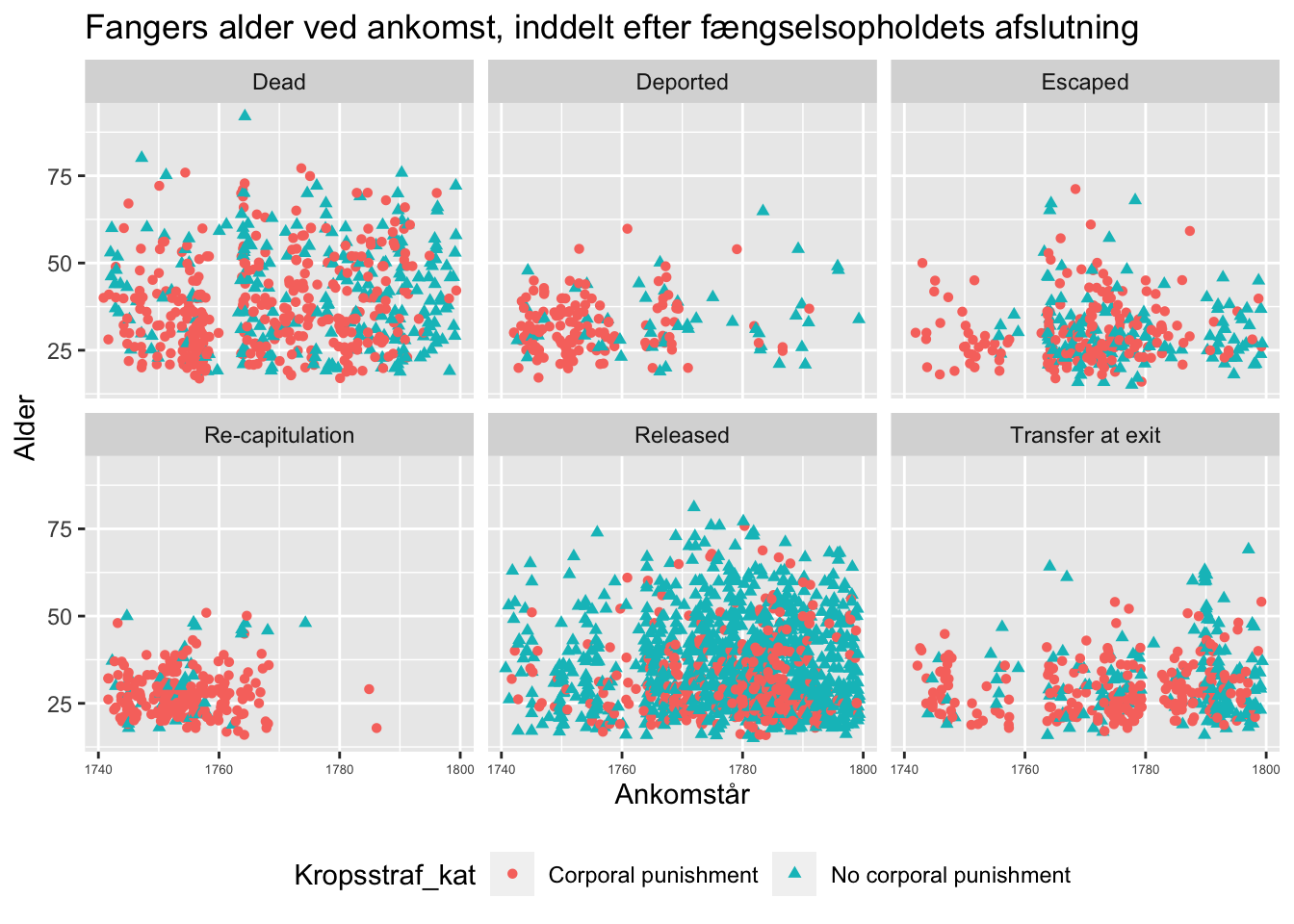
Denne visualisering er ekstremt mættet. Den inviterer til nøje læsning og kan især være stimulerende for os selv. Det er os, der har viljen til at nærstudere og spekulere over, hvorfor ting fordeler sig som de gør. Og så kan vi ellers sidde der og tænke over, hvorfor de fanger, hvis fængselsophold ender med re-kapitulation (indledning af en ny militær tjenesteperiode), har en anden profil, end dem, der løslades på regulær vis. Og hvad fortæller udviklingen hos de flygtede os? Og så videre…
Men vi skal nok ikke bede andre end vores vejleder om at kigge på den i denne form. Vores vejleder har måske tålmodigheden (hvis det er en god dag). Af andre er det meget at forlange.
4.4 Datafornemmelse
De diagram- og geomtyper vi har gennemgået ovenfor er klassikere af en grund. Det er visualiseringstyper, der er lette at afkode, fordi vi som modtagere kender deres konventioner. Med få tilpasninger og velovervejede valg om, hvordan vi knytter kompleksitet til visuelle komponenter, kan vi dermed få visualiseringer, der kan læses let og præcist. Men det er ikke altid det vi vil. En datavisualisering kan også handle om at give vores læser en mere intuitiv fornemmelse for data. I sådanne tilfælde vil vi i mindre grad vægte præcision og klarhed.
Lad os prøve en type af visualisering, der af og til findes i videnskabelig kommunikation.
library(ggstream)
# Først skal vi skabe en dataframe med Afslutninger pr år.
df_exits <- df %>%
mutate(Afslutningsår = year(Slutdato)) %>%
filter(Afslutningsår > 1749, Afslutningsår < 1800) %>%
select(Afslutning, Afslutningsår) %>%
na.omit() %>%
mutate(Afslutningsår = as.factor(Afslutningsår),
Afslutning = as.factor(Afslutning)) %>%
group_by(Afslutningsår, Afslutning, .drop = FALSE) %>%
summarise(n = n()) %>%
na.omit()
# Herefter en visualisering
ggplot(df_exits) +
geom_stream(aes(x = as.numeric(as.character(Afslutningsår)),
y = n,
fill = Afslutning),
colour = 1,
linewidth = 0.1,
type = "mirror",
bw = 0.50,
sorting = "onset") +
scale_fill_brewer(palette = "Pastel1") +
theme_light() +
theme(panel.grid.major.y = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
panel.border = element_rect(fill = "transparent"),
legend.background = element_blank()) +
xlab("") + ylab("Antal afslutninger") +
ggtitle("1700-talsfængslets udveje")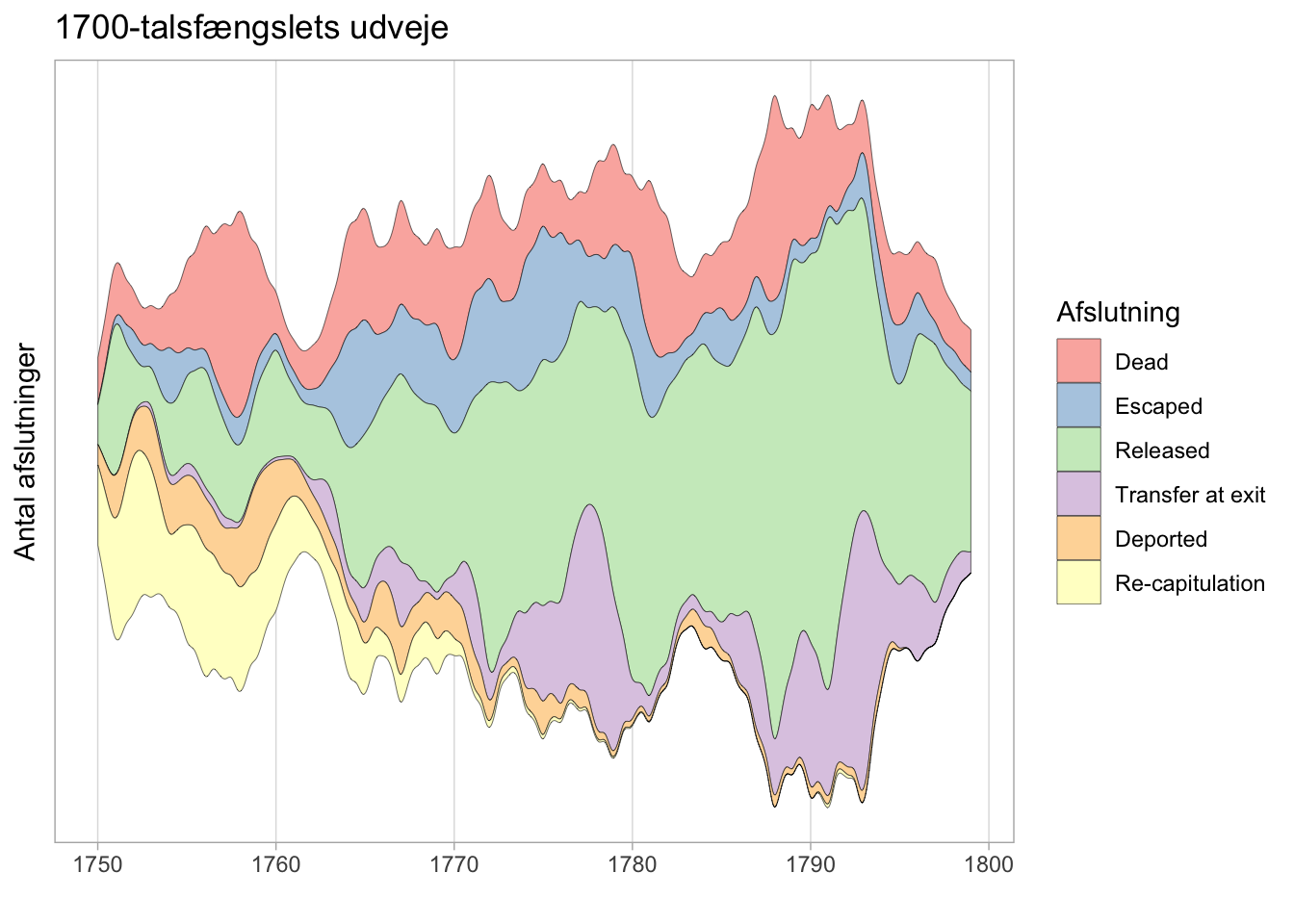
Ulemperne er tydelige. Grafen udjævner kurverne til en grad, hvor en præcis aflæsning er besværliggjort. For at guide læseren væk fra en sådan læsning, har vi tilmed gjort en kardinalsynd og fjernet størrelsesangivelserne på y-aksen. På denne måde guider vi vores læser til ikke at forsøge at læse grafen med analytisk præcision, men at tænke at lade dem forstå den mere intuitivt - at facilitere fornemmelse frem for præcision.
4.5 En grammatikøvelse
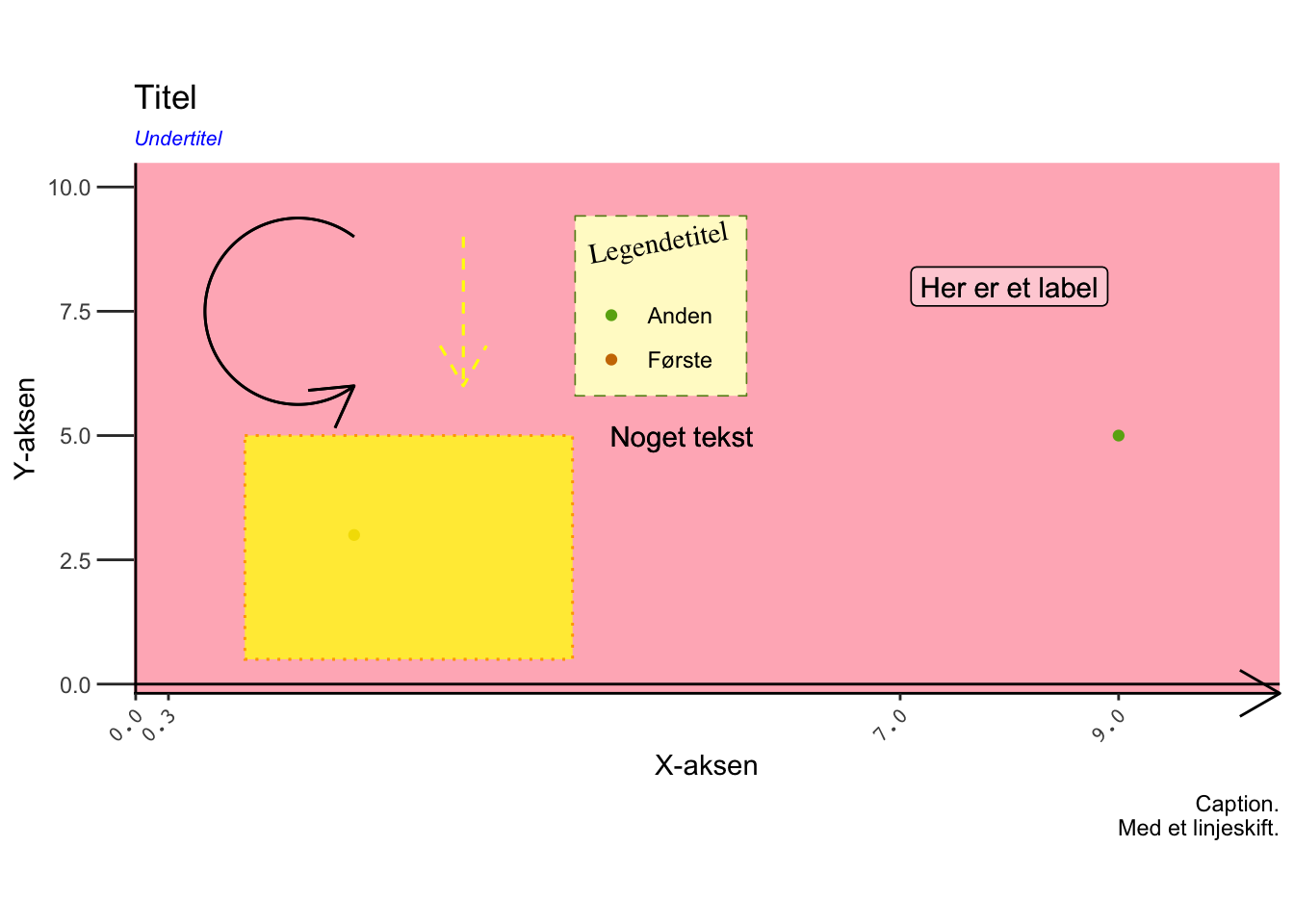
Ofte har vi ikke svært ved at visualisere vores data, men vi kan bruge evigheder på at rode rundt for at få styr på placeringen af vores legende eller for at ændre på et enkelt elements farve. Øvelsen handler derfor om alle de dele af en visualisering, der ikke knytter sig til data. Først loader vi tidyverse. Vi skaber også noget dummy-data.
a = c(2, 9)
b = c(3, 5)
c = c("Første", "Anden")
df_dummy = data.frame(a, b, c)
tekst_streng = "Noget tekst"Lad os bygge et plot manuelt, og customize en lang række parametre:
ggplot(df_dummy, aes()) +
geom_point(aes(x = a, y = b, colour = c )) +
geom_hline(yintercept = 0, linewidth = 0.5) +
geom_vline(xintercept = 0, linewidth = 0.5) +
geom_rect(xmin = 1, xmax = 4, ymin = 0.5, ymax = 5,
colour = "orange",
fill = "yellow",
alpha = 0.5,
linetype = "dotted") +
coord_cartesian(xlim = c(0.46, 10), ylim = c(0.3, 10)) +
geom_text(label = tekst_streng, x = 5, y = 5) +
geom_label(label = "Her er et label", x = 8, y = 8, alpha = 0.2) +
geom_curve(x = 2, xend = 2, y = 9, yend = 6, arrow = arrow(),
ncp = 100, curvature = 2, angle = 90) +
geom_segment(x = 3, xend = 3, y = 9, yend = 6, arrow = arrow(),
linetype = "dashed", color = "yellow") +
labs(title = "Titel",
subtitle = "Undertitel",
x = "X-aksen",
y = "Y-aksen",
caption = "Caption.\n Med et linjeskift.",
colour = "Legendetitel") +
theme(legend.position = "bottom") +
scale_colour_manual(values = c(Første = "#CC7800", Anden = "#69AD12")) +
scale_x_continuous(breaks = c(0, 0.3, 7, 9, 11), minor_breaks = NULL) +
theme(plot.subtitle = element_text(face = "italic",
colour = "blue",
size = 8),
legend.background = element_rect(fill = "lemonchiffon",
linewidth = 0.3,
colour = "olivedrab",
linetype = "dashed"),
legend.key = element_blank(),
legend.justification = c(0.1, 1),
legend.position = c(0.4, 0.9),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
plot.background = element_blank(),
panel.background = element_rect(fill = "lightpink"),
axis.ticks.length.y = unit(0.2, "inches"),
axis.text.x = element_text(family = "mono",
angle = 45,
vjust = 1,
hjust = 1),
legend.title = element_text(family = "serif",
angle = 10),
aspect.ratio = 1 / 2.16,
axis.line.x = element_line(arrow = arrow()))