library(tidyverse)
library(readxl)
library(quanteda)
library(tidytext)
library(wordcloud)
viser <- read_csv2("data/Viser.csv")8 Kollokationer, stopord og tokenisering
Dette kapitel bygger videre på det forrige, men peger på andre standard-elementer i arbejdet med tekst, end dem vi finder str_funktionerne. Til sidst vil kapitlet introducere en simpel på at visualisere ord-frekvenser, dvs. deres hyppighed i en given sammenhæng.
8.1 Setup
Vi starter med at loade pakker og data. Dataene er viser trykt i forbindelse med henrettelser i 1700-tallet. Datasættet er skabt af Emilie Luther Valentin og kan udforskes med øjnene her.
8.2 Keyword in context
Et simpelt greb i en eksplorativ analyse er at kigge på ord i deres umiddelbare kontekst. Dette gøres ved at definere konteksten som et vindue af ord, der kommer før og efter det ord, der interesserer ord. Pakken Quanteda indeholder funktionen kwic, der netop sigter på denne måde at søge i tekstdata. Man kalder ofte resultatet for sådan en metode for “kollokationer”.
synd_i_kontekst <- kwic(tokens(viser$Text, remove_punct = TRUE),
pattern = "synd",
window = 5,
valuetype = "regex")
head(synd_i_kontekst)Keyword-in-context with 6 matches.
[text1, 6] Et ynckeligt Klagemaal Hvilket groff | Synderinde |
[text1, 104] sidste Dage Thi jeg har | syndet |
[text1, 122] oc Taare heed Offver mine | Synder |
[text1, 137] selvom mone høris Paa denne | syndig |
[text1, 273] Gud jeg for slig et | syndig |
[text1, 407] har leffvet I hvilcken jeg | Syndsens |
ved Nafn Anna Corporals Udfører
groffvelig Som jeg maa selff
groffve 2 Thi Jeg beganget
Verdens Jord Jeg monne der
Spil Tilbørlig Straff maa lide
Barn Saavidt mon vær inddrefvetHer søger vi efter en simpel term “synd”, men vi kunne også have søgt efter en regular expression. Bemærk at kwic ikke skelner mellem store og små bogstaver. Argumentet “window” angiver hvor mange ord før og efter søgetermen, der skal inkluderes.
Funktionen giver os noget, der ligner en dataframe, men det er den ikke. For at vi kan arbejde videre med resultatet må vi derfor lave denne tabel om til en almindelig dataframe (som dem vi hidtil har arbejdet med). I samme ombæring kan vi genskabe hele tekstrengen, der pt. er opdelt på tværs af kolonnerne “pre” (de 5 ord, der leder op til søgetermen) “keyword” (selve søgetermen) og “post” (de 5 ord, der kommer efter søgetermen).
synd_i_kontekst <- as.data.frame(synd_i_kontekst) %>%
mutate(Text = paste(pre, keyword, post)) %>%
select(Text, docname)
head(synd_i_kontekst) Text
1 Et ynckeligt Klagemaal Hvilket groff Synderinde ved Nafn Anna Corporals Udfører
2 sidste Dage Thi jeg har syndet groffvelig Som jeg maa selff
3 oc Taare heed Offver mine Synder groffve 2 Thi Jeg beganget
4 selvom mone høris Paa denne syndig Verdens Jord Jeg monne der
5 Gud jeg for slig et syndig Spil Tilbørlig Straff maa lide
6 har leffvet I hvilcken jeg Syndsens Barn Saavidt mon vær inddrefvet
docname
1 text1
2 text1
3 text1
4 text1
5 text1
6 text1Voila! Her får vi altså en søgeterm og de ord, denne optræder i forlængelse af. Som en indledende manøvre kan dette hjælpe os med at åbne et stort tekstkorpus op og generere spørgsmål til videre undersøgelse.
8.3 Tokenisering
En standardoperation i mange sammenhænge er “tokenisering”. I det ovenstående har vi allerede tokeniseret teksten, men uden at se det tokeniserede resultat. Hvad betyder “tokenisering”? Helt basalt betyder det, at teksten splittes op i mindre, sammenlignelige enheder (deraf “token”).
Den mest almindelige form for “token” er ganske simpelt det enkelte ord. Tokenisering skaber en ny struktur i vores data, hvor hver række svarer til et enkelt ord. En teksts sekvens ender dermed som en serie af rækker. Vi kan bruge funktionen unnest_tokens fra pakken tidytext til at skabe denne datastruktur.
synd_tokens <- synd_i_kontekst %>%
unnest_tokens(Ord, Text)
head(synd_tokens) docname Ord
1 text1 et
2 text1 ynckeligt
3 text1 klagemaal
4 text1 hvilket
5 text1 groff
6 text1 synderindeLæg mærke til, hvordan teksten nu er splittet op i rækker. Dette gør det let at lave bearbejdning på ordniveau. F.eks. kan vi meget let nu tælle, hvor mange gange de enkelte ord optræder i vores tekstkorpus:
token_count <- synd_tokens %>%
group_by(Ord) %>%
summarise(antal = n()) %>%
arrange(desc(antal))
head(token_count, 10)# A tibble: 10 × 2
Ord antal
<chr> <int>
1 og 158
2 jeg 141
3 synd 122
4 i 101
5 synder 77
6 som 75
7 mig 74
8 gud 64
9 til 60
10 at 57Bemærk, at dette ikke er en bearbejdning af vores fulde tekstdata, men derimod af de tekststrenge vi skabte gennem vores keyword-in-context-søgning.
8.4 Stopord
Optællingen af tokeniserede ord viser noget ganske åbenlyst: Mange af de hyppigste ord er ikke specielt sigende. På dansk ville vi måske kalde dem for “fyldord”. Dem kan vi filtrere fra, så vi kun står tilbage med de ord, der faktisk synes at bære meningen i teksten. Det gør vi ved at loade en stopordsliste. “Stopord” er ord, der skal sorteres fra i vores analyse.
stopord <- read_excel("data/stopord.xlsx")
head(stopord, 10)# A tibble: 10 × 1
Ord
<chr>
1 af
2 alle
3 at
4 bemeldte
5 blive
6 da
7 de
8 den
9 der
10 det Stopordslisten er kontekstspecifik. Der findes generiske stopordslister, men kontekst betyder noget (især for historikere), og hvad der bærer mening er ofte netop defineret af kontekst. Det er let at lave sin egen stopordsliste. Det er faktisk bare et simpelt Excel-ark med en enkelt kolonne “Ord”.
Vi kan bruge denne stopordsliste til at filtrere vores tokeniserede datasæt. Det kan vi, fordi vi kan matche stopordslistens kolonne med “Ord” med kolonnen “Ord” i vores datasæt. Fordi de to kolonner hedder det samme kan tidyverses join-funktioner automatisk matche. For at filtrere skal vi bruge det såkaldte anti_join, der leder efter matches og så fjerner rækker, der matcher. Dermed bliver vores fyldord matchet med stopordslisten, hvorefter de filtreres fra.
token_count <- token_count %>%
anti_join(stopord)Joining with `by = join_by(Ord)`head(token_count, 10)# A tibble: 10 × 2
Ord antal
<chr> <int>
1 synd 122
2 synder 77
3 gud 64
4 synden 50
5 syndere 41
6 syndig 40
7 synde 32
8 syndsens 31
9 arme 21
10 hielp 16Det var straks meget bed. Vi har dog stadig en masse ord, der indeholder “synd” eller en variation deraf. Kan du regne ud hvorfor? Og hvordan kunne det være undgået?
8.5 Visualisering af ordfrekvenser
Tokeniseringen af tekstdata og optællingen af ord kan visualiseres. En simpel, og nogle gange parodieret, visualisering er den såkaldte “wordcloud” - en sky af ord, hvis størrelse typisk svarer til deres hyppighed. En wordcloud er dog ofte svær at læse, så det giver i de fleste tilfælde bedre mening at lave et søjlediagram.
Undtagelsen er, at en wordcloud kan bruges til at visualisere ord i flere forskellige kontekster, ved at farvekode dem. Et eksempel, der kunne være relevant i denne kontekst, kunne være, at vise de ord, der indgår i konteksten af to forskellige termer, f.eks. “gud” og “satan”. Her kan vi også gøre nytte af, at vores kwic-søgeterm kan være en regular expression, for satan findes i mange former: satan, sathan, djævel, diefuel osv.
gud_kontekst <- kwic(tokens(viser$Text, remove_punct = TRUE, remove_numbers = TRUE),
pattern = "gud",
window = 8,
valuetype = "regex") %>%
as.data.frame() %>%
mutate(Text = paste(pre, post)) %>%
unnest_tokens(Ord, Text) %>%
anti_join(stopord) %>%
group_by(Ord) %>%
summarise(antal = n(),
keyword = "Gud")Joining with `by = join_by(Ord)`satan_kontekst <- kwic(tokens(viser$Text, remove_punct = TRUE, remove_numbers = TRUE),
pattern = "sa(th|t)an|d(i|æ)(f|v|u)",
window = 8,
valuetype = "regex") %>%
as.data.frame() %>%
mutate(Text = paste(pre, post)) %>%
unnest_tokens(Ord, Text) %>%
anti_join(stopord) %>%
group_by(Ord) %>%
summarise(antal = n(),
keyword = "Satan")Joining with `by = join_by(Ord)`gud_satan <- rbind(gud_kontekst, satan_kontekst) %>%
arrange(desc(antal))head(gud_satan, 20)# A tibble: 20 × 3
Ord antal keyword
<chr> <int> <chr>
1 gud 59 Gud
2 hielp 32 Gud
3 naade 31 Gud
4 bud 29 Gud
5 arme 27 Gud
6 siæl 25 Gud
7 syndere 25 Gud
8 synd 24 Gud
9 ord 23 Gud
10 naadig 20 Gud
11 gode 16 Gud
12 synder 16 Gud
13 verden 16 Gud
14 aand 15 Gud
15 guds 15 Gud
16 gud 15 Satan
17 ach 14 Gud
18 død 13 Gud
19 lod 13 Satan
20 dit 12 Gud Gud fylder mere end Satan i vores tekster. Det er ikke overraskende, for de er trods alt fra 1700-tallet. For at kunne visualisere er vi nødt til at tildele dem en farve. Dette skyldes, at vi ikke vil visualisere med ggplot, men med en anden funktion. Denne kan ikke automatisk tildele farver.
gud_satan <- gud_satan %>%
mutate(farve = if_else(str_detect(keyword, "Satan"), "red", "olivedrab"))
head(gud_satan, 10)# A tibble: 10 × 4
Ord antal keyword farve
<chr> <int> <chr> <chr>
1 gud 59 Gud olivedrab
2 hielp 32 Gud olivedrab
3 naade 31 Gud olivedrab
4 bud 29 Gud olivedrab
5 arme 27 Gud olivedrab
6 siæl 25 Gud olivedrab
7 syndere 25 Gud olivedrab
8 synd 24 Gud olivedrab
9 ord 23 Gud olivedrab
10 naadig 20 Gud olivedrabNu kan vi lave vores wordcloud.
wordcloud(gud_satan$Ord,
gud_satan$antal,
max.words = 120,
random.order = FALSE,
colors = gud_satan$farve,
ordered.colors = TRUE)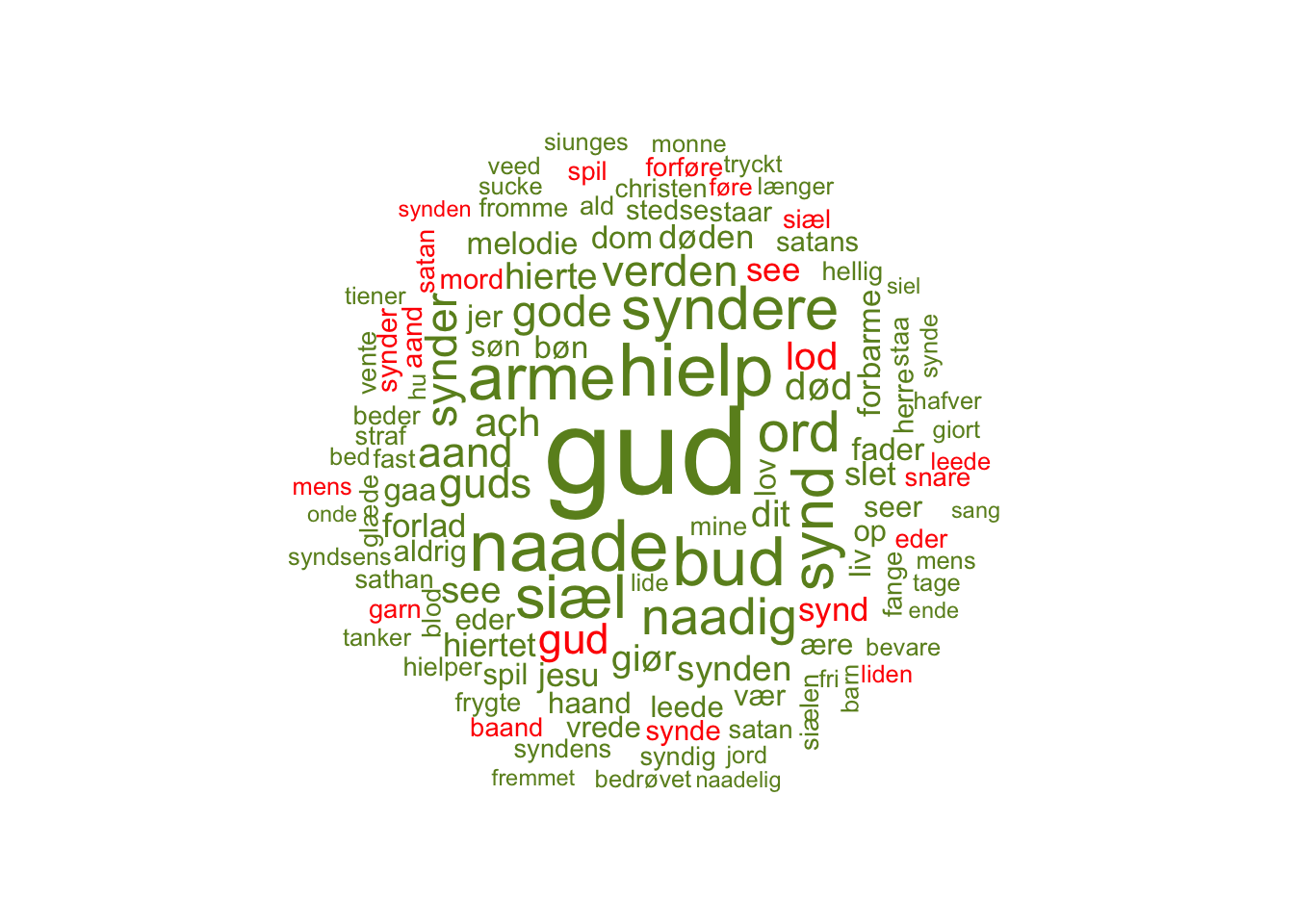
Resultatet kan vi begynde at læse intuitivt. Hvad fortæller det os f.eks. at “Gud” er det største røde ord, men at satan langt fra er størst blandt de grønne?
8.6 Tokenisering i bigrams
Jeg nævnte ovenfor, at tokenisering på ordniveau er meget almindeligt. Der er dog ingen grund til, at vi ikke kan skabe tokens, der er noget andet. Et simpelt eksempel kunne være et såkaldt “bigram” - en ordforbindelse. Typisk er et bigram en forbindelse imellem to ord, der følger hinanden direkte i en tekst. Lad os prøve at finde bigrams i konteksten af satan.
satan_kontekst <- kwic(tokens(viser$Text, remove_punct = TRUE),
pattern = "sa(t|th)an|d(i|j)æv",
window = 8,
valuetype = "regex") %>%
as.data.frame() %>%
mutate(Text = paste(pre, keyword, post))
satan_bigrams <- satan_kontekst %>%
unnest_tokens(bigrams, Text, token = "ngrams", n = 2) %>%
select(bigrams, docname)
head(satan_bigrams, 10) bigrams docname
1 af den text2
2 den samme text2
3 samme mand text2
4 mand hand text2
5 hand qvinden text2
6 qvinden nedlagde text2
7 nedlagde og text2
8 og satan text2
9 satan mig text2
10 mig sagde text2Vi kan optælle dem:
bigrams_count <- satan_bigrams %>%
group_by(bigrams) %>%
summarise(antal = n()) %>%
arrange(desc(antal))
bigrams_count# A tibble: 2,281 × 2
bigrams antal
<chr> <int>
1 af satan 10
2 at hand 8
3 synd og 6
4 af satans 5
5 at jeg 5
6 i synd 5
7 satan mig 5
8 sathan hand 5
9 af sathan 4
10 af sathans 4
# … with 2,271 more rowsStopordene fylder igen meget. Det er lidt mere besværligt at filtrere dem fra, men princippet er det samme. Vi er bare nødt til at splitte vores bigram op i to separate kolonner i processen og matche disse kolonner med kolonnen “Ord” i stopordslisten.
satan_bigrams_filtered <- satan_bigrams %>%
separate(bigrams, c("word1", "word2"), sep = " ") %>%
anti_join(stopord, by = c("word1" = "Ord")) %>%
anti_join(stopord, by = c("word2" = "Ord")) %>%
mutate(bigrams = paste(word1, word2, sep = " "))
satan_bigrams_count <- satan_bigrams_filtered %>%
group_by(bigrams) %>%
summarise(antal = n()) %>%
arrange(desc(antal))
satan_bigrams_count# A tibble: 465 × 2
bigrams antal
<chr> <int>
1 satans snare 4
2 ak satan 3
3 hellig aand 3
4 satans baand 3
5 satans garn 3
6 egen haand 2
7 folk forføre 2
8 fule giæst 2
9 fuule aand 2
10 lod forføre 2
# … with 455 more rowsHer får vi nogle ordpar, der gør os klogere på, hvad man taler om, når man taler om djævlen.