Netværksanalyse og visualisering nyder stadig større popularitet i historifaget. Dette er en simpel guide til, hvordan man bruger R til netværksvisualisering. Som eksempel benytter jeg data vedrørende flugt fra fængslet Trunken i perioden fra 1720 til 1732. Trunken var Danmarks første fængsel. Det lå placeret ved kongens flådeværft Bremerholmen i hjertet af København. Her udførte dømte mænd strafarbejde for staten. I perioden var fængslet plaget af oprør og kollektive flugtforsøg, der til sidst gjorde myndighederne så bekymrede, at fængslet blev nedlagt. Fangerne blev flyttet væk fra dette militærstrategiske knudepunkt som konsekvens af den frygt, deres handlinger affødte. De data, der visualiseres i denne guide handler om disse hændelser. Kapitlet her er en kort teknisk indførsel i netværksvisualisering.
Der findes dedikeret software til netværksvisualisering, f.eks. Gephi. Denne software er i mange sammenhænge glimrende, men ofte vil vores netværksvisualisering være et led i en større udforskning af data, hvor vi også benytter andre teknikker. Derfor kan det være en fordel at kunne visualisere direkte i R (eller Python). Som en introduktion til grundlæggende termer og greb i netværkanalyse anbefaler jeg Andreas Birkbak og Anders Kristian Munks kapitel om netværk i deres håndbog Digitale metoder (Hans Reitzels Forlag, 2017).
6.1 Data
For at komme igang skal vi loade noget data ind i vores session. Lad os ved denne lejlighed også kigge på et brudstykke af dette data.
Vores data består af en dataframe (Unrest_edgelist), der reelt er en såkaldt edgelist. Hver række repræsenterer en forbindelse (en “edge”) imellem to punkter (kaldet “nodes”). Hver node er repræsenteret ved et ciffer i en af de to kolonner. Dette ciffer er et ID på en person i vores andet datasæt, der optegner alle fanger i fængslet (Convict_df). En forbindelse imellem to personer eksisterer således i vores data, hvis personerne optræder i samme række i Unrest_edgelist. En sådan forbindelse indikerer, at de to personer har været indblandet i samme flugt eller oprør i fængslet. Helt basalt er personer således forbundne, fordi de har været med i det samme komplot. Antagelsen er, at flugt eller oprør er alvorlige handlinger, så man gør dem kun med fanger man har en relation til. Der er ingen retning på forbindelserne, så de betyder det samme uanset om person a eller b kommer først. Dataene siger heller ikke noget om, hvilken rolle en fange har haft i en hændelse, blot at vedkommende var involveret.
Komplotterne er identificeret vha. fængslets mandtal, hvor fangers forsvinden er noteret systematisk og igennem forhørsprotokoller fra standretter holdt over fanger, der var involveret i flugtplaner, der aldrig blev realiseret eller i forskellige oprør. Der kan være mange metodiske problemer herved, men da kilderne er ganske udførlige er det rimeligt at antage, at vi kender til de så godt som alle flugter og de fleste større oprør blandt fanger i perioden. Ofte kommer vores data om relationer ikke pakket og parat som en edgelist. I så fald vil det være nødvendigt at bearbejde dem, så de får et tilsvarende format. Alternativt kan netværksgrafer også produceres fra matricer. Det efterfølgende arbejde vil være det samme uanset.
6.2 Fra data til visualiseret graf
Først og fremmest skal vi have lavet et objekt, der efterfølgende kan visualiseres. Til det bruger vi funktioner fra pakken Tidygraph.
# A tbl_graph: 140 nodes and 858 edges
#
# A directed simple graph with 26 components
#
# Node Data: 140 × 1 (active)
name
<chr>
1 592
2 599
3 602
4 604
5 605
6 614
# … with 134 more rows
#
# Edge Data: 858 × 2
from to
<int> <int>
1 1 5
2 1 15
3 2 17
# … with 855 more rows
Ved at køre funktionen as_tbl_graph() på vores edgelist skabes en graf. Reelt består den af to hovedkomponenter, der kan ses ovenfor, nemlig to tabeller: en (Node Data) indeholder noderne, dvs. vores personer, og en anden (Edge data) indeholder forbindelserne. Groft sagt har vi splittet vores edgelist i to. Hvis vi vil bearbejde en enkelt af disse tabeller, kan vi gøre det ved hjælp af funktionen activate(nodes) eller activate(edges). Eksempler på dette findes løbende i kodestykkerne nedenfor. Hvorfor er det smart med denne opdeling i to separate tabeller, når vores oprindelige edgelist faktisk kunne indeholde samme information i en enkelt tabel? Jo, det er smart, fordi vi nu kan begynde at føje til de to tabeller. Her kan vi f.eks. udregne forskellige indikatorer, der kan fortælle om hver enkelt person står centralt i netværket og gemme disse værdier i relation til hver person. Vi kan også koble forskellige variable til hver node, f.eks. informationer om den enkelte person. Vores data over fanger indeholder netop sådanne informationer.
Lad os starte med at visualisere netværksgrafen, før vi når for langt. Hvordan ser vores netværk ud? Til selve visualiseringen kan vi bruge pakken ggraph, der kan visualisere netværksobjekter med udgangspunkt i verber, du måske allerede kender fra ggplot.
library(ggraph)Flugtnetværk %>%ggraph(layout ="fr") +geom_edge_link(color ="grey") +geom_node_point() +ggtitle("Netværk over fanger i komplot, 1720-1732") +theme_void()
Warning: Using the `size` aesthetic in this geom was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` in the `default_aes` field and elsewhere instead.
Hvad fortæller denne visualisering os? Måske først og fremmest, at en lang række af hændelserne var forbundne qua personoverlap. Det vil sige, at de samme fanger gik igen på tværs af flugtforsøg og oprør. Samtidig fortæller visualiseringen, at der også foregik en lang række hændelser, der ikke havde forbindelse hertil, der synes at have involveret færre personer. De er nok typiske flugter. Fangerne havde altså langt fra ligemeget del i urolighederne.
Bemærk ggraphs argument “layout”. Dette specificerer hvilken algoritme, der benyttes til at placere noderne i relation til hinanden. Valget af layout-algoritme er langt fra trivielt. Med ggraph er der indbygget en række algoritmer, der har forskellige forkortelser eller betegnelser: “fr”, kk”, “dh”, “stress”, “graphopt”, “lgl”, “drl”, “linear”, “circle”, “sphere”, “gem”, “randomly” m.fl. Prøv at bytte “fr” ud med nogle af de andre i ovenstående stykke kode. Algoritmerne er gode til forskellige ting. Man kan læse op på hvordan de virker eller prøve sig lidt frem. Læg mærke til, at visualiseringerne bruger tilfældighed og er non-deterministiske. Vores visualisering ser mao. forskellig ud, for hver gang vi kører den. Hvis man vil undgå dette, kan man bruge funktionen set_seed(). Hvad fortæller visualiseringen os intet om? Først og fremmest fortæller den ikke noget om de fanger, der enten flygtede alene eller aldrig flygtede. Visualiseringen giver måske indtryk af at kortlægge et helt fællesskab, men det er altså ikke tilfældet. Denne type informationer skal vi altid sørge for at kommunikere til vores læsere. Ellers risikerer vi, at visualiseringen, der jo skal gøre en kompleks struktur overskuelig, ender med at vildlede og give det forkerte indtryk af forbindelser.
6.3 Tilføjelse af attributer
For at visualisere med udgangspunkt i variable vedr. den enkelte person, skal dette data føjes til vores grafs undertabel Node Data. Det gør vi ved hjælp af et simpelt left_join().
# A tbl_graph: 140 nodes and 858 edges
#
# A directed simple graph with 26 components
#
# Node Data: 140 × 4 (active)
name Navn Afslutning Baggrund
<chr> <chr> <chr> <chr>
1 592 Niels Jensen Skaaning Transfer at exit Army
2 599 Magnus Bendixsen / Mogens Released Civilian
3 602 Jep Madsen Escaped Civilian
4 604 Trond Jansen Transfer at exit Civilian
5 605 Ole Hansen Escaped Civilian
6 614 Michael Henrich Escaped Army
# … with 134 more rows
#
# Edge Data: 858 × 2
from to
<int> <int>
1 1 5
2 1 15
3 2 17
# … with 855 more rows
Nu kan vi se, at vores tabel over Node Data indeholder kolonnerne fra vores Convict_df dataframe. Dem kan vi bruge som æstetiske værdier i vores visualisering. Lad os prøve!
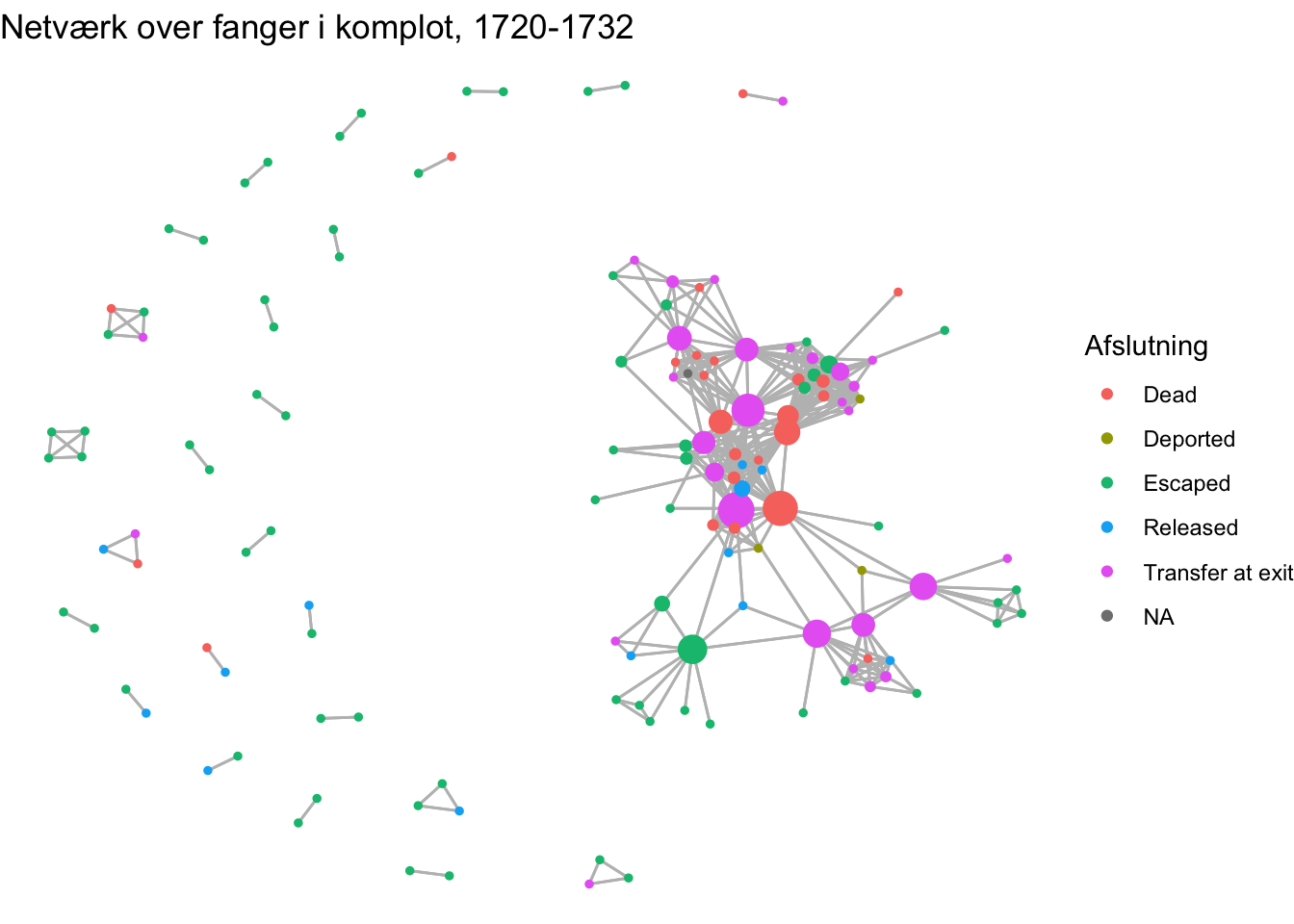
library(ggraph)Flugtnetværk %>%ggraph(layout ="fr") +geom_edge_link(color ="grey") +geom_node_point(aes(colour = Afslutning)) +ggtitle("Netværk over fanger i komplot, 1720-1732") +theme_void()
Her ser vi samme netværk, men farven indikerer, hvordan fængselsopholdet afsluttedes for de involverede fanger. Vi kan se, hvordan de mindre og isolerede flugtforsøg blev gjort af fanger, der også afsluttede selve fængselsopholdet ved at flygte uden at blive fanget. Mindre flugtforsøg havde tilsyneladende en bedre chance for at lykkes end store. Vi ser også, at mange af de fanger, der er involveret i de forbundne grupper blev forflyttet og at nogle få blev deporteret. Dette var ellers langt fra hyppige afslutninger på et fængselsophold, der typisk endte med enten død eller løsladelse, hvis fangen altså ikke lykkedes med at flygte. Dette kan bruges til at generere en ny hypotese: Forflyttede myndighederne fanger, der skabte problemer i fængslet? Hvad antyder visualiseringen, hvis vi i stedet knytter farve til fangernes baggrund.
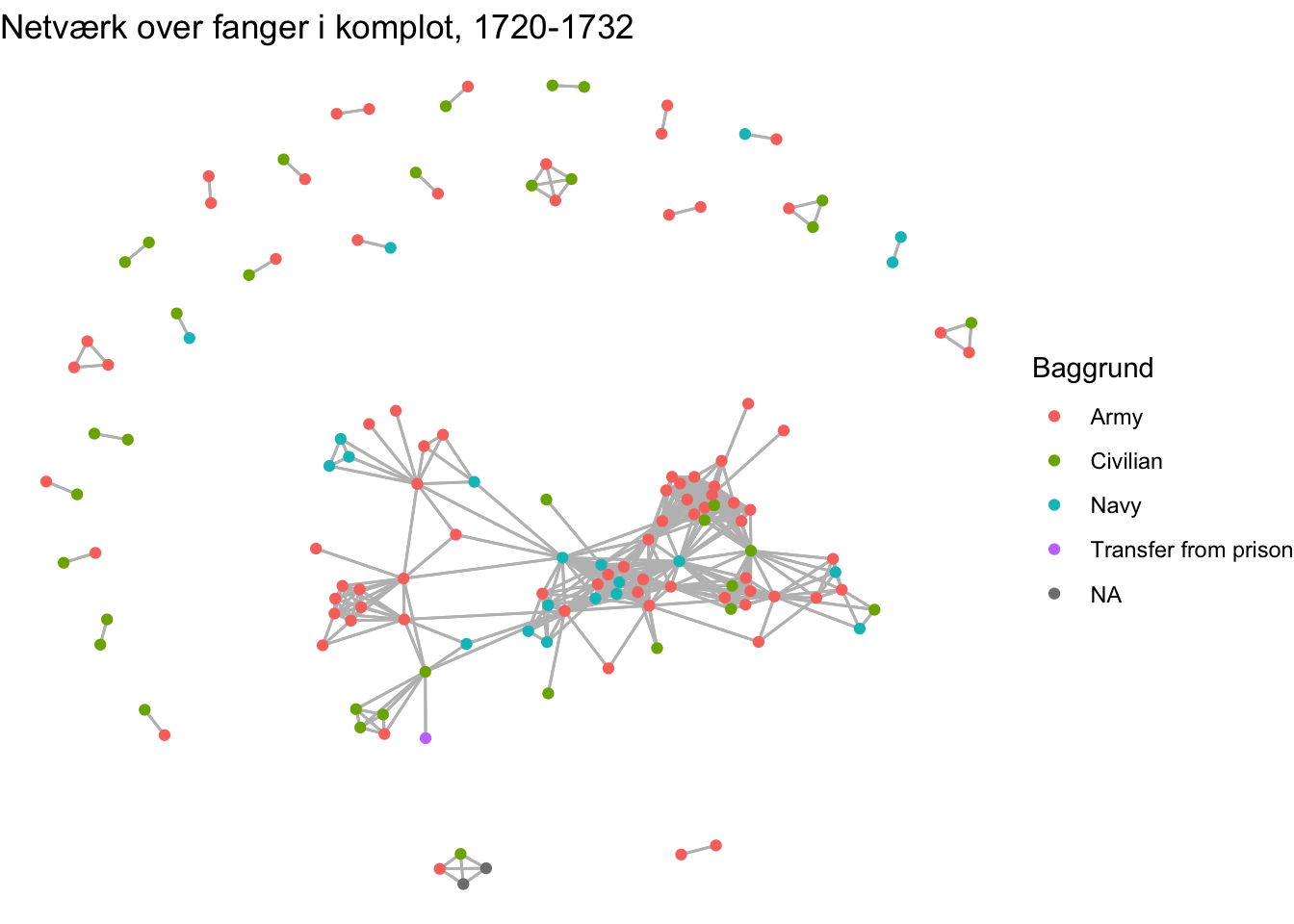
Flugtnetværk %>%ggraph(layout ="fr") +geom_edge_link(color ="grey") +geom_node_point(aes(colour = Baggrund)) +ggtitle("Netværk over fanger i komplot, 1720-1732") +theme_void()
Det lader til, at der er en overvægt af eks-militære fanger i den tætforbundne del af netværket, imens de mindre flugtforsøg fremstår mere blandede. Kigger vi nærmere på de forbundne hændelser, er der også noget, der tyder på, at der var kliker, der delvist harmonerede med bestemte baggrunde. Perioden, der undersøges, fulgte i kølvandet på Store Nordiske Krig og der var mange soldater i fængslet. De kom fra en rå kultur, hvor desertion var en del af soldatens repertoire og handlemåder. Var disse komplotter mon en forlængelse heraf? På denne måde kan vi altså bruge visualisering, der inkluderer attributer, eksplorativt. På baggrund af de mønstre vi kan se, danner vi nye hypoteser om forbindelserne i vores materiale. En anden tilgang er at visualisere med udgangspunkt i indikatorer, der fortæller noget om den enkelte nodes strukturelle placering i netværket. I netværksanalysen findes en lang række måder, hvorpå centralitet og autoritet udregnes.
Flugtnetværk %>%activate(nodes) %>%mutate(centralitet =centrality_betweenness()) %>%ggraph(layout ="fr") +geom_edge_link(color ="grey") +geom_node_point(aes(size = centralitet)) +ggtitle("Netværk over fanger i komplot, 1720-1732") +theme_void() +theme(legend.position ="none")
I koden ovenfor skabes vha. funktionerne mutate() og centrality_betweenness() en kolonne i vores Node Data, der udregner en centralitetsindikator for hver node. Her er der tale om såkaldt “betweenness”-centralitet, der visuelt er markeret ved størrelsen på den enkelte node. Når vi udregner “betweenness”, finder vi typisk de noder, der forbinder forskellige, distinkte grupper. Eksemplet fremhæver således de fanger, der var med i flere komplotter, der ellers ikke havde udpræget overlap. Måske kan vi tænke dem som kulturbærere, der selv når en flugt mislykkedes bar viden og tanker videre ind i nye grupper og forsøg. Det vil så være relevant at spørge, om det var netop disse skikkelser, myndighederne forflyttede for at stoppe uroen?
Det er der måske noget, der antyder. Hvilke billeder tegner sig med andre centralitetsindikatorer? Vi kunne bruge centrality_degree, centrality_pagerank, eller centrality_closeness, der udregner en nodes vigtighed i et netværk på forskellige måder. Husk, at de scorer, der følger af udregningerne ender i en kolonne og efterfølgende kan bruges som data til andre explorative eller statistiske greb, f.eks. til clustering eller som led i en faktoranalyse.
6.4 Det æstetiske
En af de klare attraktioner ved netværksvisualisering er, at de drager øjet og derved fanger læserne til at interessere sig for vores data. Netværksvisualiseringen er derfor ikke blot et eksplorativt værktøj, der kan hjælpe, når vi skal stille kvalificerede spørgsmål om sammenhænge i vores materiale. Det kan også tjene til at kommunikere disse sammenhænge. Derfor hjælper det os, hvis visualiseringerne er pæne.
Det er de ovenstående ikke. Der skal lidt arbejde til, men R lader os customize stort set alle parametre i vores visualisering. Ved hjælp af forskellige geom_edge_-funktioner kan vi få forbindelserne til at bøje og dreje. Der findes også en lang række andre geoms, så vi kan plotte f.eks. tekst. Det er altså først og fremmest vores forestillingsevne, der skal på prøve.
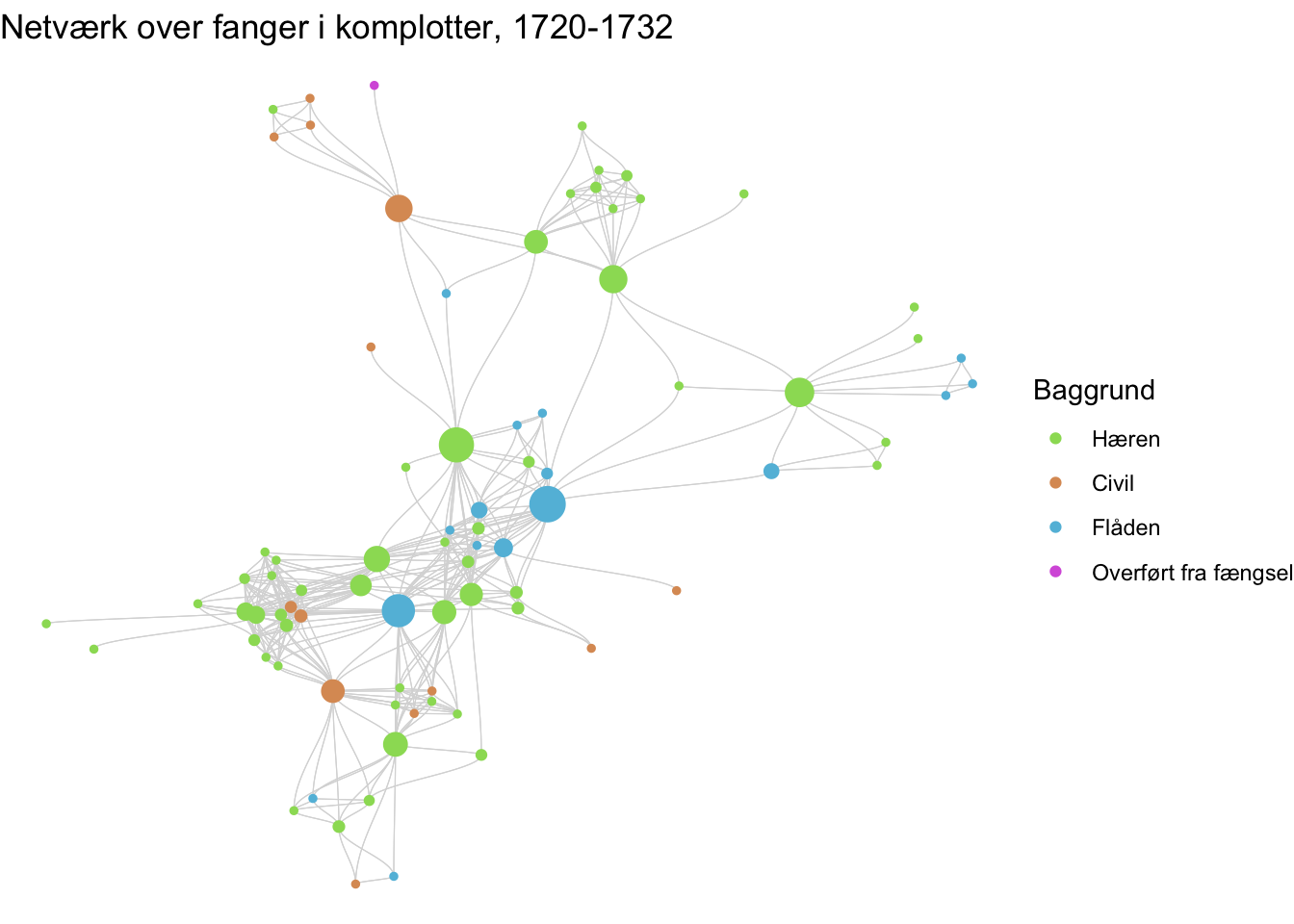
Lad os som afslutning udforske nogle enkelte af disse muligheder. Vi kan starte med at filtrere de mindre grupper væk, så vi kan fokusere på gruppen, der er involveret i de forbundne episoder. Nedenfor ses et eksempel, hvor dette er gjort, og hvor de æstetiske parametre er sat med henblik på at gøre grafens forbindelser lettere at følge. Vi vil gerne kommunikere grafens kompleksitet, men vores visualiserings kompleksitet skal afspejle kompleksitet i vores data.
library(viridisLite)#Filtrering baseret på gruppe. Group_components tildeler noder et tal baseret på hvilken "subgraph" de er del af. Tallene indekserer således, så noder der er forbundne i den største subgraph altid får gruppenummeret 1)Flugtnetværk_main <- Flugtnetværk %>%activate(nodes) %>%mutate(group =group_components()) %>%filter(group ==1)# Ny visualiseringFlugtnetværk_main %>%activate(nodes) %>%mutate(centralitet =centrality_betweenness()) %>%ggraph(layout ="fr", niter ="100") +geom_edge_diagonal2(color ="grey85", strength =0.7, width =0.2) +geom_node_point(aes(size = centralitet, colour = Baggrund)) +ggtitle("Netværk over fanger i komplotter, 1720-1732") +scale_size(guide ="none") +scale_colour_manual(values =c("#9ADC63", "#DC9A63", "#63BDDC", "#D763DC"),labels =c("Hæren", "Civil", "Flåden", "Overført fra fængsel")) +theme_void()
Der kunne gøres meget andet, men dette er en start. Ofte ser man også, at netværksvisualiseringer i udgivelser annoteres for at pege på forskellige træk ved netværket. Dette gøres lettest i egentlig illustrationssoftware, især hvis den annoterede tekst skal formatteres pænt.
Det er altså bare at komme igang. Ofte vil vores datasæt allerede indeholde forbindelser, der kan visualiseres og udforskes. Husk også, at det ikke blot er personer og deres relationer, man kan tegne med disse værktøjer. Hvorfor ikke se på forbindelser mellem steder, genstande eller ord?